티스토리 뷰
CPU cache
cpu cache란?
cache memory는 속도가 빠른 장치와 느린 장치 사이에서 속도차에 따른 병목 현상을 줄이기 위한 범용 고속 buffer 메모리를 지칭합니다(SRAM이라고도 합니다). CPU에서는 CPU 코어와 메모리 사이에서 속도차에 따른 병목 현상을 완화하는 역할을 합니다. 프로그램에서 직접적으로 읽거나 쓸 수 없고 하드웨어의 메모리 관리 시스템이 내부적으로 제어합니다. 대부분의 프로그램은 한번 사용할 데이터를 다시 사용할 가능성이 높고, 그 주변의 데이터도 곧 사용할 가능성이 높은 데이터 지역성을 가지고 있습니다. 데이터 지역성을 활용하여 메인 메모리에 있는 데이터를 캐시 메모리에 불러와 두고, CPU가 필요한 데이터를 캐시에서 먼저 찾도록 하면 성능을 향상시킬 수 있습니다.
여기서 잠깐 메모리의 참조 지역성(principal of locality)에 대해 알아보고 가겠습니다.
참조 지역성의 3가지 기본형 : 시간(temporal), 공간(spatial), 순차(sequential) 지역성
공간(spatial) 지역성
특성 클러스터의 기억 장소들에 대해 참조가 집중적으로 이루어지는 경향으로, 참조된 메모리 근처의 메모리를 참조합니다.
시간(temporal) 지역성
최근 사용되었던 기억 장소들이 집중적으로 액세스되는 경향으로, 참조했던 메모리는 빠른 시간에 다시 참조될 확률이 높습니다.
순차(sequential) 지역성
데이터가 순차적으로 액세스되는 경향으로, 프로그램 내의 명령어가 순차적으로 구성되어 있다는 것이 대표적인 경우입니다. 공간 지역성에 편입되어 설명되기도 합니다.
캐시메모리의 특징

-
캐시는 주기억장치와 CPU사이에 위치하며, 자주 사용하는 프로그램과 데이터를 기억합니다.
-
캐시 메모리는 메모리 계층 구조에서 가장 빠른 소자이며, 처리속도가 거의 CPU의 속도와 비슷할 정도의 속도를 가지고 있습니다.
-
캐시메모리를 사용하면 주 기억장치를 접근하는 횟수가 줄어들어 컴퓨터의 처리속도가 향상됩니다.
-
캐시 주소표는 검색시간을 단축시키기 위해 주로 연관기억장치를 사용합니다.
-
캐시의 크기는 보통 수십 KByte ~ 수백 KByte입니다.
캐시메모리의 매핑 프로세스
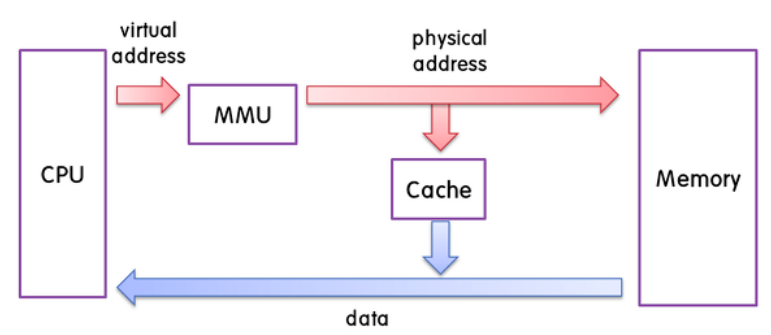
CPU가 메모리 주소를 사용하여 메모리로 데이터를 받으려고 합니다. 하지만 CPU가 쓰는 주소는 가상 메모리 주소로 메모리 입장에서는 이해할 수없는 구조를 가지고 있습니다. 그래서 중간에 메모리 관리 장치(MMU)가 가운데에서 번역을 하여 메모리가 이해 할 수 있는 물리 주소로 변환을 해줍니다. 그리고 캐시에 해당 주소에 대한 데이터가 있는지 확인을 하는데, 캐시에 데이터를 저장하는 방식에 따라 물리주소를 다르게 해석 할 수 있습니다.
매핑 프로세스는 주기억장치로부터 캐시 메모리로 데이터를 전송하는 방법을 말하는 것으로 3가지 방법이 있습니다.
직접 매핑(direct Mapping)

주기억장치의 블록들이 지정된 한 개의 캐시 라인으로만 사상될 수 있는 매핑 방법입니다.간단하고 구현하는 비용이 적게드는 장점이 있지만 적중률이 낮아질 수 있다는 단점이 있습니다.
우선 메인 메모리에서 캐시로 데이터를 저장할 시에 참조의 지역성 때문에 한번 받아올 때, 인접한 곳까지 한꺼번에 캐시 메모리에 저장하고 이때 단위를 블록(Block)이라고 합니다. 그리고 캐시는 메인 메모리의 몇번째 블록인지 알려주는 태그(Tag)도 함께 저장합니다.
메모리 주소 중에 가장 뒷부분(붉은색)은 블럭의 크기를 의미합니다. 지금 블럭의 크기가 4이므로 뒤의 두자리를 사용하여 블럭의 크기를 표현하였습니다. 그리고 이 영역은 블럭에 몇 번째에 원하는 데이터가 있는지 보여주는 지표가 되어줍니다. 만일 위의 예에서 붉은 영역이 01이라면 블록의 두 번째 내용을 CPU에서 요청한 것입니다.
같은 라인에 위치하는 데이터는 파란색 색찰한 영역에 의하여 구별이 가능합니다. 예를 들면 메모리의 첫번째 요소 00000과 다섯번째 주소 00100은 캐시내에 같은 위치에 자리잡고 있어서 구별이 필요로 한데, 앞의 세자리 000과 001로 구별을 할 수 있습니다.
이와 같은 요소의 활용은 캐시 메모리에 저장된 데이터 중 내가 원하는 것이 있는지 없는지 확인 가능합니다. 캐시의 태그와 주소상의 태그가 동일한지 확인한 후 같으면 붉은 영역을 통해 데이터를 읽습니다. 만일 태그가 다르다면 메모리에서 데이터를 가지고 옵니다.
직접 매핑은 위의 사진처럼 캐시에 저장된 데이터들을 메인 메모리에서 동일한 배열을 가지도록 매핑하는 방법을 말합니다. 이화 같은 방식을 사용하기 때문에 매우 단순하고 탐색이 쉽다는 장점이 있습니다. 하지만 적중률(Hit ratio)가 낮다는 단점이 있다. 반복문을 사용할 때 같은 라인의 00000를 불렀다가 그다음엔 00100을 부른다면 캐시에 빈번하게 변경이 발생할 수 있습니다.
어소시에이티브 매핑(Associative Mapping)
직접 매핑 방식의 단점을 보완한 방식입니다. 모든 태그들을 병렬로 검사하기 때문에 복잡하고 비용이 높다는 단점이 있어 거의 사용하지 않습니다.
세트-어소시에이티브 매핑(Set-Associative Mapping)
직접 매핑과 연관 매핑의 장점만을 취한 방식입니다.
쓰기 정책
캐시에 저장되어 있는 데이터에 수정이 발생했을 때 그 수정된 내용을 주기억장치에 갱신하기 위해 시기와 방법을 결정하는 것을 말합니다.
Wite-Through
캐시에 쓰기 동작이 이루어질 때마다 캐시 메모리와 주기억장치의 내용을 동시에 갱신하므로 쓰기 동작에 걸리는 시간이 가장 깁니다.
Wite-Back
캐시에 쓰기 동작이 이루어지는 동안은 캐시의 내용만이 갱신되고, 캐시의 내용이 캐시로부터 제거될 때 주기억장치에 복사됩니다.
CPU에서 메모리에 대한 쓰기 요청 시 캐시에서만 쓰기 작업과 그 변경 사실을 확인할 수 있는 표시(dirty)를하여 놓은 후 캐시로부터 해당 블록의 내용이 제거될 때 그 블록을 메인 메모리에 복사함으로써 메인 메모리와 캐시의 내용을 동일하게 유지하는 방식입니다.
Write-Once
캐시에 쓰기 동작이 이루어질 때 한번만 기록하고 이후의 기록은 모두 무시합니다.
지금 시간이 없어서 나머지는 다음에..