티스토리 뷰
태스크란?

-
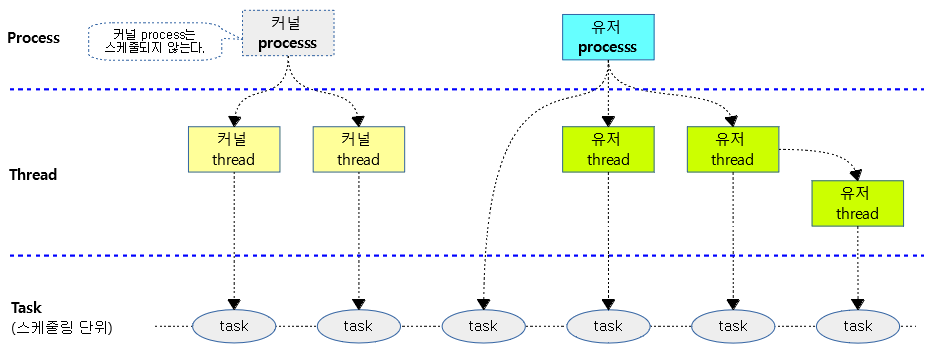
프로세스
- 리눅스 개발자 입장에서 프로세스는 리눅스 시스템 메모리에 적재되어 실행을 대기하거나 실행하는 실행 흐름을 의미합니다. 더 자세히 말하면 파일 시스템에서 메모리로 로드한 코드, 데이터(프로그램)와 이를 커널에서 관리하기 위한 task_struct 구조체를 말하며 커널이 제공하는 방법을 통하지 않고서는 다른 프로세스와 상호작용하지 않으며(shared_memory) 한 프로세스의 잘못된 동작이 다른 프로세스에 영향을 미치지 않는 각각의 테스크입니다. 리눅스 커널에서는 프로세스와 스레드를 구별하지 않고 전부 태스크로 인식합니다(별다른 설정이 없을 경우).
- OS 커널이 부트업되어 준비된 경우 유저 레벨에서 디스크로부터 application을 로드하여 자원(메모리, 파일, 페이징, 시그널, 스택, …)을 할당하여 동작시킬 수 있는 최소 단위입니다. 프로세스는 사용 중인 파일, 데이터, 프로세서 상태, 메모리 영역 주소 공간, 스레드 정보, 전역 데이터가 저장 된 메모리 부분 등 수 많은 자원을 포함하는 개념입니다. 생성시 프로세스별 스택이 생성됩니다.
- 유저 레벨에서 요청하여 OS 커널이 준비하고 생성합니다.
- 특별히 OS 커널은 그 자체가 하나의 커널 프로세스라고도 할 수 있습니다.
- 커널 프로세스는 부트업타임에 생성되고 종료 직전까지 소멸되지 않으며 스케줄링 단위에는 포함되지 않는 특성으로 인해 존재 유무가 확연히 드러나지 않습니다.
- 다수 프로세스를 실시간으로 사용하는 기법을 멀티프로세싱이라고 말하며 같은 시간에 멀티 프로그램을 실행하는 방식을 멀티태스킹이라고 합니다.
-
스레드
- 일반적인 정의는 프로세스에서 실행 단위만 분리한 상태입니다
- 이 때문에 경량 프로세스 (LWP, Light-Weight Process)로도 불립니다.
- 참고: 메인스트림 OS로 레벨업「리눅스 커널2.6」| ZDnet Korea
- 아키텍처를 다루는 문서에서 사용하는 스레드는 하드웨어 스레드를 의미하며 명령들을 수행할 수 있는 최소단위 장치인 core 또는 virtual core입니다.
- 예) core 당 2개의 하이퍼 스레드(x86에서의 virtual core)를 가진 4 core의 하드웨어 스레드는 총 8개입니다.
- OS 레벨에서의 스레드는 Process 내부에서 생성되는 더 작은 단위의 소프트웨어 스레드를 의미합니다.
- 커널 코드에서는 사용위치에 따라 스레드가 하드웨어 스레드를 의미할 수도 있고 소프트웨어 스레드를 의미할 수도 있으므로 적절히 구분해서 판단해야 합니다.
- 리눅스 버전 2.6에서 전적으로 커널이 스레드를 관리하고 생성한다. 따라서 이 기준으로 설명하였습니다.
- 최종적으로 Red-hat팀이 개발한 NPTL(Native POSIX Thread Library)을 채용하였습니다.
- 유저 스레드라고 불려도 커널이 생성하여 관리하는 것에 주의해야 한다. 리눅스 커널 2.6 이전에는 프로세스를 clone하여 사용하거나 유저 라이브러리를 통해 만들어 사용한 진짜 유저 스레드입니다.
- 참고: Native POSIX Thread Library | Wikipedia
- 프로세스가 할당 받은 자원을 공유하여 사용할 수 있다. 단 스택 및 TLS(Thread Local Storage) 영역은 공유하지 않고 별도로 생성합니다.
- 유저 스레드는 유저 프로세스 또는 상위 스레드로 부터 생성됩니다.
- 특별히 커널 스레드는 유저 레벨이 아닌 OS 커널 레벨에서만 생성 가능합니다.
- 일반적인 정의는 프로세스에서 실행 단위만 분리한 상태입니다
-
태스크
- 프로세스나 스레드를 리눅스에서 스케줄링 할 수 있는 최소 단위가 태스크입니다.
- 유저 태스크에서 스케줄링에 대한 비율을 조정하는 경우 nice 값을 사용하여 각 태스크의 time slice를 산출해냅니다.
- 내부 자료 구조에서는 struct task_struct가 테스크를 나타내고 그 내부에 스케줄 엔티티 구조체를 포함하며 이 스케줄 엔티티를 사용하여 time slice를 계산합니다.
- 태스크에는 스케줄러별로 사용할 수 있도록 3 개의 스케줄 엔티티인 sched_entity, sched_rt_entity 및 sched_dl_entity가 있습니다.
- cgroup을 사용한 그룹 스케줄링을 하는 경우에는 스케줄 엔티티가 태스크 그룹(group scheduling)에 연결되어 time slice를 계산합니다.
- 내부 자료 구조에서는 struct task_struct가 테스크를 나타내고 그 내부에 스케줄 엔티티 구조체를 포함하며 이 스케줄 엔티티를 사용하여 time slice를 계산합니다.
- 유닉스와 다르게 리눅스의 경우 별도의 설정이 없는 경우 프로세스와 스레드가 동일한 태스크 표현을 사용하고 스케줄링 비율은 동일합니다.
멀티태스킹 (time slice, virtual runtime)
동시에 2개의 태스크를 하나의 CPU에서 구동을 시키면 이론적으로는 그 CPU에서 50%의 파워로 2 개의 태스크그가 동시에 병렬로 동작해야 하는데 실제 하드웨어 CPU는 한 번에 하나의 태스크 밖에 수행할 수 없으므로 시간을 분할(time slice) 한 그 가상 시간(virtual runtime) 만큼 교대로 수행을 하여 만족시킵니다.
우선순위
Priority
- 커널에서 분류하여 사용하는 우선순위로 0~139까지 총 140 단계가 있습니다.
- priority 값이 작을수록 높은 우선순위로 time slice를 많이 받습니다.
- 0~99까지 100 단계는 RT 스케줄러에서 사용합니다.
- 100~139까지의 40단계는 CFS 스케줄러에서 사용합니다.
- Nice로 변환되는 영역입니다.
Nice
- POSIX 표준이 지정하였다. 일반적인 태스크에서 지정할 수 있는 -20 ~ +19 까지 총 40단계가 있습니다.
- nice 값이 가장 작은 -19가 우선 순위가 더 높고 time slice를 많이 받습니다.
- priority 값으로 변환 시 100 ~ 139의 우선순위를 갖습니다.
- RT 스케줄러에서 사용하는 priority 0 ~ 99값보다 커서 RT 스케줄러보다는 항상 낮은 우선 순위를 갖습니다.
- root 권한이 아닌 유저로 프로세스나 스레드가 생성되면 스케줄링 단위인 태스크의 nice 값은 0으로 시작됩니다.
- 2003년에 +19 레벨의 time slice는 1ms(1 jiffy)와 동일하게 설정을 하였으나 그 후 HZ=1000인 시스템(데스크탑)에서 time slice가 너무 적어 5ms로 변경하였습니다.
스케줄러
커널에 디폴트로 5개의 스케줄러가 준비되어 있고 사용자 태스크는 스케줄 정책을 선택하는 것으로 각각의 스케줄러를 선택할 수 있습니다. 단 stop 스케줄러 및 Idle-task 스케줄러는 커널이 자체적으로만 사용하므로 사용자들은 선택할 수 없습니다.
- Stop 스케줄러
- Deadline 스케줄러
- RT 스케줄러
- CFS 스케줄러
- Idle Task 스케줄러
스케줄 정책
- SCHED_DEADLINE
- 태스크를 deadline 스케줄러에서 동작하게 합니다.
- SCHED_RR
- 같은 우선 순위의 태스크를 default 0.1초 단위로 round-robin 방식을 사용하여 RT 스케줄러에서 동작하게 합니다.
- SCHED_FIFO
- 태스크를 FIFO(first-in first-out) 방식으로 RT 스케줄러에서 동작하게 합니다.
- SCHED_NORMAL
- 태스크를 CFS 스케줄러에서 동작하게 합니다.
- SCHED_BATCH
- 태스크를 CFS 스케줄러에서 동작하게 한다. 단 SCHED_NORMAL과는 다르게 yield를 회피하여 현재 태스크가 최대한 처리를 할 수 있게 합니다.
- SCHED_ILDE
- 태스크를 CFS 스케줄러에서 가장 낮은 우선순위로 동작하게 합니다. (nice 19보다 더 느리다. nice=20)

설명에 앞서 모르시는 분들을 위해 간단히 앞으로 나올 용어를 설명하도록 하겠습니다.
timeslice
- 스케줄러가 프로세스에게 부여한 실행 시간입니다.
- 프로세스마다 실행할 수 있는 단위 시간을 부여하는데 이를 타임 슬라이스라고 부릅니다. 프로세스는 주어진 타임 슬라이스를 다 소진하면 컨택스트 스위칭 됩니다.
vruntime
- 프로세스가 그동안 실행한 시간을 정규화한 시간 정보입니다.
- cfs는 런큐에 실행 대기 상태에 있는 프로세스 중 vruntime이 가장 적은 프로세스를 다음에 실행할 프로세스로 선택합니다. 우선 순위가 높은 프로세스는 우선 순위가 낮은 프로세스에 비해 vruntime이 더 서서히 증가합니다. 즉, 우선 순위가 높은 프로세스가 낮은 프로세스에 비해 vruntime이 덜 증가한다는 것입니다.
- 프로세스는 자신의 태스크 디스크립터 &se.vruntime 필드에 vruntime 정보를 저장합니다.
CFS 스케줄러
- linux v2.6.23부터 사용하기 시작하였습니다.
- timeline(다음 태스크 실행할 마감 시간)으로 정렬한 RB 트리를 사용합니다.
- p->se.vruntime을 키로 소팅됩니다.
- 기존에 사용하던 active, expired 배열은 사용하지 않습니다.
- 3가지 스케줄 정책에서 사용됩니다.
- SCHED_NORMAL
- SCHED_BATCH
- SCHED_IDL
- 기존 O(1) 스케줄러는 jiffies나 hz 상수에 의존하여 ms 단위를 사용하였으나 cfs 스케줄러는 ns 단위로 설계되었습니다.
- 통계적 방법을 사용하지 않고 deadline 방식으로 관리합니다.
- CFS bandwidth 기능을 사용할 수 있습니다.
- 예) ksoftirqd나 high 우선 순위 워크큐의 워커로 동작하는 kworker 태스크들은 CFS 스케줄러에서 nice -20으로 동작합니다.
리얼타임(RT) 스케줄러
-
sched_rt_period_us
-
실행 주기 결정 (초기값: 1000000 = 1초)
-
이 값을 매우 작은 수로 하는 경우 시스템이 처리에 응답할 수 없습니다.
-
hrtimer보다 작은 경우 등
-
-
-
sched_rt_runtime_us
-
실행 시간 결정 (초기값: 950000 = 0.95초)
-
전체 스케줄 타임을 100%로 가정할 때 95%에 해당하는 시간을 RT 스케줄러가 이용할 수 있습니다.
-
-
2가지 스케줄 정책에서 사용됩니다.
- SCHED_FIFO
- cfs 스케줄러에서 사용하는 weight 값 및 time slice라는 개념이 없다. 스스로 슬립하거나 태스크가 종료되기 전 까지 계속 동작합니다.
- SCHED_RR
- SCHED_FIFO와 거의 동일하다. 같은 우선 순위의 태스크가 존재하는 경우에만 디폴트 0.1초 단위로 라운드 로빈 방식으로 순회하며 동작합니다.
- SCHED_FIFO
- 0번부터 99번까지 100개의 우선 순위 리스트 배열로 관리됩니다.
- RT bandwidth 기능을 사용할 수 있습니다.
- 예) migration, threaded irq 및 watchdog 태스크들은 rt 스케줄러에서 동작합니다.
Deadline 스케줄러
- 1가지 스케줄 정책에서 사용됩니다.
- SCHED_DEADLINE
- 아직 사용자 드라이버에서는 잘 활용되고 있지 않습니다.
런큐
- CPU 마다 하나 씩 사용됩니다.
- 런큐에는 각 스케쥴러들이 사용됩니다.
- CPU에 배정할 태스크들이 스케줄 엔티티 형태로 런큐에 enqueue 됩니다.
- 태스크가 처음 실행될 때 가능하면 부모 태스크가 위치한 런큐에 enqueue 됩니다.
- 같은 cpu에 배정되는 경우 캐시 친화력이 높아서 성능이 향상됩니다.

Time Slice
CFS에서의 weight
CFS 스케쥴러에서 사용하는 nice 우선순위에 따라서 weight 값이 부여됩니다.
- nice가 0인 태스크에 대한 weight 값을 1024 기준 값으로 하였습니다.
- 실수 1.0의 weight 값을 2진 정수로 표현할 때 2^10=1024를 사용하였습니다.
- 정밀도는 10진수로 표현하는 경우 1.000에 해당하는 소숫점 3자리를 커버합니다.
- 64비트 시스템에서는 scale 1024를 적용하여 nice 0에 대한 값이 2^20=1,048,576을 사용하여 정밀도를 더 높였습니다.
- nice 값이 1씩 감소할 때마다 10%의 time slice 배정을 더 받을 수 있도록 25%씩 weight 값이 증가됩니다.
- 참고로 가장 우선 순위가 낮은 idle 스케줄러에서 사용하는 idle 태스크의 경우 time slice를 가장 적게 받는 3으로 배정하여 고정하였습니다.
다음 테이블은 nice -> weight의 빠른 산출을 위해 미리 계산하여 만들어둔 테이블입니다.

다음 테이블은 nice -> wmult의 빠른 산출을 위해 미리 계산하여 만들어둔 테이블입니다.
- time slice를 계산할 때 나눗샘 대신 곱셈으로 처리하려고 weight 값을 inverse한 값을 사용합니다.
- 성능향상을 목적으로 커널은 x / weight = y와 같은 산술식을 사용하여야 할 때 나눗셈을 피해서 아래 테이블 값을 사용하여 x * wmult >> 32로 y 값을 산출합니다.
- 예) ‘4096 / 1024 = 4′ 와 ‘4096 * 4194304 >> 32 = 4’에 대한 결과는 서로 동일한 결과를 얻을 수 있음을 알 수 있습니다.

아래 그림과 같이 weight가 25% 증가 시 실제 cpu 점유율이 기존에 비해 10%가 증가됨을 확인할 수 있습니다.
- 단 2개 태스크를 비교할 때의 기준이고 3개 이상의 태스크를 비교할 때에는 똑같이 10%가 증가되지 않음을 확인할 수 있습니다.

다음 그림은 5개의 task에 대해 각각의 nice 값에 따른 weight 값과 그 비율을 산출하였다. 완벽한 등차수열의 차이는 보이지 않지만 비슷한 양상을 보이고 있습니다.

스케줄링 latency 와 스케일 정책
런큐에서 동작하는 태스크들이 한 바퀴 돌도록 사용할 periods(ns)는 다음 변수를 사용하여 산출됩니다. 여기서 latency란 데이터를 요청하여 나올때 까지 걸리는 대기시간입니다.
-
rq->nr_running
- 런큐에서 동작중인 태스크 수입니다.
-
factor
- 스케일링 정책에 따른 비율입니다. (rpi2: factor=3)
-
sched_latency_ns
- 최소 스케줄 기간으로 디폴트 값(6000000) * factor(3) = 18000000(ns)
- “/proc/sys/kernel/sched_latency_ns”
-
sched_min_granularity
- 태스크 하나 당 최소 스케쥴 기간으로 디폴트 값(750000) * factor(3) = 2250000(ns)
- “/proc/sys/kernel/sched_min_granularity_ns”
-
sched_wakeup_granularity_ns
- 태스크의 wakeup 기간으로 디폴트 값(1000000) * factor(3) = 3000000(ns)
- “/proc/sys/kernel/sched_wakeup_granularity_ns”
-
sched_nr_latency
- sched_latency_ns를 사용할 수 있는 태스크 수입니다.
- 이 값은 sched_latency_ns / sched_min_granularity 으로 자동 산출됩니다.
스케줄링 latency 산출식
산출은 nr_running와 sched_nr_latency를 비교한 결과에 따라 다음 두 가지 중 하나로 결정됩니다.
- sysctl_sched_latency(18ms) <- 조건: nr_running <= sched_nr_latency(8)
- sysctl_sched_min_granularity(2.25ms) * nr_running <- 조건: nr_running > sched_nr_latency(8)
다음 그림은 rpi2(cpu:4) 시스템에서 하나의 cpu에 태스크가 5개 및 10개가 구동될 떄 각각의 스케줄링 기간을 산출하는 모습을 보여줍니다.

cpu 수에 따른 스케일링 정책
스케일링 정책에 따른 비율이며 cpu 수에 따른 스케일 latency에 변화를 주게됩니다.
- SCHED_TUNABLESCALING_NONE(0)
- 항상 1을 사용하여 스케일이 변하지 않게 합니다.
- SCHED_TUNABLESCALING_LOG(1)
- 1 + ilog2(cpus)과 같이 cpu 수에 따라 변화됩니다. (디폴트)
- rpi2: cpu=4개이고 이 옵션을 사용하므로 factor=3이 적용되어 3배의 스케일을 사용합니다.
- SCHED_TUNABLESCALING_LINEAR(2)
- online cpu 수로 8 단위로 정렬하여 사용합니다. (8, 16, 24, 32, …)
태스크별 Time Slice
개별 태스크가 수행한 시간을 산출합니다.
- 런큐별 스케줄링 latency 1 주기 기간을 각 태스크의 weight 비율별로 나눕니다.

VRuntime
태스크의 vruntime은 개별 태스크 실행 시간을 누적시킨 값을 런큐의 RB 트리에 배치하기 위해 로드 weight을 반대로 적용한 값입니다. (우선 순위가 높을 수록 누적되는 weight 값을 반대로 작게하여 vruntime에 추가하므로 RB 트리에서 먼저 우선 처리될 수 있게 합니다.)
누적시 추가될 virtual runtime slice는 다음과 같이 산출됩니다.
vruntime slice = time slice * wieght-0 / weight

다음 그림은 4개의 태스크가 idle 없이 계속 실행되는 경우 각 태스크의 vruntime은 산출된 vruntime slice 만큼 계속 누적되어 실행되는 모습을 보여줍니다.

cfs_rq->min_vruntime
cfs 런큐에 새로운 태스크 또는 슬립되어 있다가 깨어나 엔큐되는 경우 vruntime이 0부터 시작하게되면 이러한 태스크의 vruntime이 가장 낮아 이 태스크에 실행이 집중되고 다른 태스크들은 cpu 타임을 얻을 수 없는 상태가 됩니다. (starvation problem) 따라서 이러한 것을 막기 위해서 cfs 런큐에 새로 진입할 때 min vruntime 값을 기준으로 사용하게 하였습니다.
- cfs_rq->min_vruntime 값은 현재 태스크와 cfs 런큐에 대기중인 태스크들 중 가장 낮은 수가 스케줄 틱 및 필요 시마다 갱신되어 사용됩니다.
- cfs 런큐에 진입 시에 min_vruntime 값을 더해서 사용하고 cfs 런큐에서 빠져나갈 때에는 min_vruntime 값만큼 감소시킵니다.
- cfs 런큐에 진입 시에 vruntime에 대해 약간의 규칙을 사용합니다.
- 새 태스크가 cfs 런큐에 진입합니다
- min_vruntime 값 + vruntime slice를 더해 사용합니다.
- fork된 child 태스크가 먼저 실행되는 옵션을 사용한 경우 현재 태스크가 우선 처리되도록 vruntime과 swap합니다.
- idle 태스크가 깨어나면서 cfs 런큐에 진입합니다.
- min_vruntime 값 사용합니다.
- 기타 여러 이유로 cfs 런큐에 진입(태스크 그룹내 이동, cpu migration, 스케줄러 변경)
- 새 태스크가 cfs 런큐에 진입합니다
다음 그림은 min_vruntime이 vruntime이 가장 낮은 curr 태스크가 사용하는 vruntime 값으로 갱신되는 모습을 보여줍니다.

CFS Group Scheduling
- cgroup의 cpu 서브시스템을 사용하여 커널 v2.6.24에서 소개되었습니다.
- 계층적 스케줄 그룹(TG: Task Group)을 설정하여 사용자 프로세스의 utilization을 조절할 수 있습니다.
- 태스크의 로드 weight 값을 관리하기 위해 스케줄 엔티티를 사용하는데 태스크용 스캐줄 엔티티와 태스크 그룹용 스케줄 엔티티(tg->se[])로 나뉩니다.
- 스케줄 그룹의 CFS bandwidth 기능을 사용하면 배정받은 시간 범위내에서의 utilization 마저도 조절할 수 있습니다.
다음 그림은 그룹 스케줄링의 유/무에 대해 비교를 하였습니다.
- 우측의 경우 루트 그룹을 만들고 그 아래에 두 개의 스케줄 그룹을 만들면 디폴트로 각각 하위 두 그룹이 50%씩 utilization을 나누게 됩니다.
- 태스크 그룹을 사용하는 경우 각 태스크 그룹마다 cpu 수 만큼 cfs 런큐가 있고 그 그룹에 속한 태스크나 태스크 그룹은 각각의 스케줄 엔티티로 봅니다.
- 우측의 경우 5개의 태스크용 스케줄 엔티티가 모두 1024의 weight 값을 갖는다고 가정할 때 root 그룹은 2개의 그룹용 스케줄 엔티티에 대한 분배를 결정하고, 각 group에서는 그룹에 소속된 task용 스케줄 엔티티에 대한 분배를 결정합니다.
- 우측의 경우 root 그룹에 2 개의 task가 추가로 실행되는 경우 root 그룹은 총 4개의 스케줄 엔티티에 대한 분배를 수행합니다.. (태스크 그룹용 스케줄 엔티티 2개 + 태스크용 스케줄 엔티티 2개)
- group-1에 해당하는 각 태스크는 6.25%를 할당받습니다.
- group-2에 해당하는 태스크는 25%를 할당받습니다.
- 그림에는 표현되지 않았지만 루트 그룹에 새로 추가된 task 6와 task 7은 각각 25%를 할당받습니다.

다음 그림은 그룹 스케줄링을 적용 시 time slice 적용 비율이 변경된 것을 보여줍니다.
- 루트 그룹 밑에 두 개의 태스크 그룹을 만들고 각각 20%, 80%에 해당하는 share 값을 설정한 경우 그 그룹 아래에서 동작하는 태스크들의 utilization을 다음과 같이 확인할 수 있습니다.

CPU Bandwidth for CFS
태스크 그룹에 할당된 time slice를 모두 사용하지 않고 일정 비율만 사용하게 하여 cpu가 스로틀링(cpu를 쉬엄 쉬엄) 할 수 있게 할 수도 있고 반대로 더 많은 cpu 할당을 받을 수 있게 할 수도 있습니다.
다음 그림은 Task 5가 할당받은 80%의 time slice 비율에서 설정된 band width에 따라 좌측은 cpu를 절반만 쓰고 스로틀링(슬립하며 쉰다) 할 수 있고, 우측은 두 개의 cpu에서 동시에 동작하게 설정된 모습을 보여줍니다.
- 즉 smp 시스템에서 quota(몫)와 period가 설정된 경우 해당 스케줄 엔티티가 사용하는 시간 범위내에서 cpu 수에 따라 각 core 마다 스로틀이 발생함을 보여줍니다.

CFS Scheduling Domain
스케줄링 그룹(sched_group)에 많은 cpu 로드가 발생하면 각 스케줄링 도메인을 통해 로드 밸런스를 수행하게 합니다.
- 계층적 구조를 통해 cpu affinity에 합당한 core를 찾아가도록 합니다.
스케줄링 도메인은 디바이스 트리 및 MPIDR 레지스터를 참고하여 cpu가 on/off 될 때마다 cpu topology를 변경하고 이를 통해 스케줄링 도메인을 구성합니다.
- 디바이스 트리 + MPIDR 레지스터 -> cpu on/off -> cpu topology 구성 변경 -> 스케줄링 도메인
cpu 토플로지의 단계는 다음과 같습니다.
- cluster
- core
- thread
스케줄링 도메인의 단계는 다음과 같습니다.
- DIE 도메인
- cpu die (package)
- MC 도메인
- 멀티 코어
- SMT 도메인
- 멀티 스레드(H/W)
다음 그림은 스케줄링 도메인과 스케줄링 그룹을 동시에 표현하였습니다. (arm 문서 참고)
- 참고로 아래 그림의 스케줄링 그룹(sched_group)과 그룹 스케줄링(task_group)은 다른 기능이므로 주의합니다.

스케줄 Tick
scheduler_tick()
kernel/sched/core.c
| 01 | /* |
| 02 | * This function gets called by the timer code, with HZ frequency. |
| 03 | * We call it with interrupts disabled. |
| 04 | */ |
| 05 | void scheduler_tick(void) |
| 06 | { |
| 07 | int cpu = smp_processor_id(); |
| 08 | struct rq *rq = cpu_rq(cpu); |
| 09 | struct task_struct *curr = rq->curr; |
| 10 |
| 11 | sched_clock_tick(); |
| 12 |
| 13 | raw_spin_lock(&rq->lock); |
| 14 | update_rq_clock(rq); |
| 15 | curr->sched_class->task_tick(rq, curr, 0); |
| 16 | update_cpu_load_active(rq); |
| 17 | raw_spin_unlock(&rq->lock); |
| 18 |
| 19 | perf_event_task_tick(); |
| 20 |
| 21 | #ifdef CONFIG_SMP |
| 22 | rq->idle_balance = idle_cpu(cpu); |
| 23 | trigger_load_balance(rq); |
| 24 | #endif |
| 25 | rq_last_tick_reset(rq); |
| 26 | } |
tick 마다 스케줄 관련 처리를 수행하고 로드 밸런스 주기가 된 경우 SCHED softirq를 호출합니다.
- 코드 라인 8~9에서 현재 cpu의 런큐 및 현재 태스크를 알아옵니다.
- 코드 라인 11에서 안정되지 않은 클럭을 사용중인 경우 per-cpu sched_clock_data 값을 현재 시각으로 갱신합니다.
- 현재 x86 및 ia64 아키텍처에서만 unstable 클럭을 사용합니다.
- 코드 라인 14 런큐 클럭 값을 갱신합니다.
- 코드 라인 15에서 현재 태스크의 스케줄링 클래스의 (*task_tick)에 등록된 콜백 함수를 호출합니다.
- task_tick_fair(), task_tick_rt(), …
- 코드 라인 16에서 현재 런큐의 cpu_load[] 값을 갱신합니다.
- 코드 라인 19에서 perf 관련 처리를 수행합니다.
- 코드 라인 22에서 현재 cpu가 idle 상태인지 여부를 런큐에 기록합니다.
- 코드 라인 23에서 로드 밸런스 주기마다 SCHED_SOFTIRQ를 발생시킵니다.
- 최대 주기는 core 수 * 0.1초
- 코드 라인 25에서 커널이 nohz full 옵션을 사용하는 경우 현재 jiffies를 런큐의 last_sched_tick에 기록해둡니다.
런큐 클럭 갱신
update_rq_clock()
kernel/sched/core.c
| 01 | void update_rq_clock(struct rq *rq) |
| 02 | { |
| 03 | s64 delta; |
| 04 |
| 05 | lockdep_assert_held(&rq->lock); |
| 06 |
| 07 | if (rq->clock_skip_update & RQCF_ACT_SKIP) |
| 08 | return; |
| 09 |
| 10 | delta = sched_clock_cpu(cpu_of(rq)) - rq->clock; |
| 11 | if (delta < 0) |
| 12 | return; |
| 13 | rq->clock += delta; |
| 14 | update_rq_clock_task(rq, delta); |
| 15 | } |
런큐 클럭 값을 갱신합니다.
- 코드 라인 7~8에서 스케줄 진행 중인 경우 불필요한 스케줄 클럭을 갱신하지 않도록 빠져나갑니다.
- 코드 라인 10~12에서 현재 스케줄 클럭과 런큐에 마지막 사용한 클럭과의 차이를 delta에 대입합니다.
- 코드 라인 13~14 런큐의 클럭에 delta를 추가 반영합니다.
- 코드 라인 14에서 irq_delta 값을 산출하여 런큐의 인터럽트 소요 클럭에 추가하여 갱신합니다. irq_delta 값 만큼 인수로 전달받은 delta 값도 감소시킨 후 런큐의 클럭 태스크에 delta 값을 더해 갱신합니다.
sched_clock_cpu()
kernel/sched/clock.c
| 01 | /* |
| 02 | * Similar to cpu_clock(), but requires local IRQs to be disabled. |
| 03 | * |
| 04 | * See cpu_clock(). |
| 05 | */ |
| 06 | u64 sched_clock_cpu(int cpu) |
| 07 | { |
| 08 | struct sched_clock_data *scd; |
| 09 | u64 clock; |
| 10 |
| 11 | if (sched_clock_stable()) |
| 12 | return sched_clock(); |
| 13 |
| 14 | if (unlikely(!sched_clock_running)) |
| 15 | return 0ull; |
| 16 |
| 17 | preempt_disable_notrace(); |
| 18 | scd = cpu_sdc(cpu); |
| 19 |
| 20 | if (cpu != smp_processor_id()) |
| 21 | clock = sched_clock_remote(scd); |
| 22 | else |
| 23 | clock = sched_clock_local(scd); |
| 24 | preempt_enable_notrace(); |
| 25 |
| 26 | return clock; |
| 27 | } |
stable 클럭을 사용하는 경우 스케줄 클럭(사이클)을 반환해옵니다. (arm 및 arm64 아키텍처는 stable 클럭을 사용합니다.)
update_rq_clock_task()
kernel/sched/core.c
| 01 | static void update_rq_clock_task(struct rq *rq, s64 delta) |
| 02 | { |
| 03 | /* |
| 04 | * In theory, the compile should just see 0 here, and optimize out the call |
| 05 | * to sched_rt_avg_update. But I don't trust it... |
| 06 | */ |
| 07 | #if defined(CONFIG_IRQ_TIME_ACCOUNTING) || defined(CONFIG_PARAVIRT_TIME_ACCOUNTING) |
| 08 | s64 steal = 0, irq_delta = 0; |
| 09 | #endif |
| 10 | #ifdef CONFIG_IRQ_TIME_ACCOUNTING |
| 11 | irq_delta = irq_time_read(cpu_of(rq)) - rq->prev_irq_time; |
| 12 |
| 13 | /* |
| 14 | * Since irq_time is only updated on {soft,}irq_exit, we might run into |
| 15 | * this case when a previous update_rq_clock() happened inside a |
| 16 | * {soft,}irq region. |
| 17 | * |
| 18 | * When this happens, we stop ->clock_task and only update the |
| 19 | * prev_irq_time stamp to account for the part that fit, so that a next |
| 20 | * update will consume the rest. This ensures ->clock_task is |
| 21 | * monotonic. |
| 22 | * |
| 23 | * It does however cause some slight miss-attribution of {soft,}irq |
| 24 | * time, a more accurate solution would be to update the irq_time using |
| 25 | * the current rq->clock timestamp, except that would require using |
| 26 | * atomic ops. |
| 27 | */ |
| 28 | if (irq_delta > delta) |
| 29 | irq_delta = delta; |
| 30 |
| 31 | rq->prev_irq_time += irq_delta; |
| 32 | delta -= irq_delta; |
| 33 | #endif |
| 34 | #ifdef CONFIG_PARAVIRT_TIME_ACCOUNTING |
| 35 | if (static_key_false((¶virt_steal_rq_enabled))) { |
| 36 | steal = paravirt_steal_clock(cpu_of(rq)); |
| 37 | steal -= rq->prev_steal_time_rq; |
| 38 |
| 39 | if (unlikely(steal > delta)) |
| 40 | steal = delta; |
| 41 |
| 42 | rq->prev_steal_time_rq += steal; |
| 43 | delta -= steal; |
| 44 | } |
| 45 | #endif |
| 46 |
| 47 | rq->clock_task += delta; |
| 48 |
| 49 | #if defined(CONFIG_IRQ_TIME_ACCOUNTING) || defined(CONFIG_PARAVIRT_TIME_ACCOUNTING) |
| 50 | if ((irq_delta + steal) && sched_feat(NONTASK_CAPACITY)) |
| 51 | sched_rt_avg_update(rq, irq_delta + steal); |
| 52 | #endif |
| 53 | } |
irq_delta 값을 산출하여 런큐의 인터럽트 소요 클럭에 추가하여 갱신합니다. irq_delta 값 만큼 인수로 전달받은 delta 값도 감소시킨 후 런큐의 클럭 태스크에 delta 값을 더해 갱신합니다.
- rq->clock과 다른 점은 현재 시각에서 irq 소요 시간을 뺀 실제 태스크에 소모한 시간만을 사용한 클럭이 rq->clock_task입니다.
- irq 소요 시간 측정 관련 코드 분석은 생략
스케줄링 클래스별 틱 처리
-
Real-Time 스케줄링 클래스
- task_tick_rt()
-
Deadline 스케줄링 클래스
- task_tick_dl()
-
Completly Fair 스케줄링 클래스
- task_tick_fair()
-
Idle-Task 스케줄링 클래스
- task_tick_idle()
-
Stop-Task 스케줄링 클래스
- task_tick_stop()