티스토리 뷰
[Qwiklabs Advanced]구글 클라우드에 웹사이트 빌드하기-2부-(Using Google Compute Engine)
로또_ 2020. 10. 10. 15:00
1부에서 이어서 설명하도록 하겠습니다. 구글 클라우드에 웹사이트 빌드하기 1부를 못 보고오신 분들은 아래의 포스팅을 보고 오시면 됩니다.
-1부-
[Qwiklabs Advanced]구글 클라우드에 웹사이트 빌드하기-1부 -(Using Google Compute Engine)
이번 포스팅에서는 Compute Engine을 이용하여 웹사이트를 빌드해볼 거예요. 내용이 많아 1,2부로 나누어서 올릴 예정입니다. 아래 목차에서 4번까지 이번에는 진행하겠습니다.Cloud Build보다 좀 복잡�
puzzle-puzzle.tistory.com
-2부-
[Qwiklabs Advanced]구글 클라우드에 웹사이트 빌드하기-2부-(Using Google Compute Engine)
1부에서 이어서 설명하도록 하겠습니다. 구글 클라우드에 웹사이트 빌드하기 1부를 못 보고오신 분들은 아래의 포스팅을 보고 오시면 됩니다. [Qwiklabs Advanced]구글 클라우드에 웹사이트 빌드하기
puzzle-puzzle.tistory.com
목차
-
1. Compute Engine API 이용하기
-
2. GCS(Google Cloud Storage) 버킷 만들기
-
3. 소스 저장소 복제하기
-
4. GCE(Google Compute Engine) instaces 생성하기
-
5. Managed Instance Groups 생성하기
-
6. 로드 밸런서 생성하기
-
7. Compute Engine 스케일링하기
-
8. 웹사이트 업데이트하기
Create Managed Instance Groups
애플리케이션의 확장을 허용하기 위해 관리되는 instance 그룹이 생성되어야 하고 프론트엔드 및 백엔드 instance를 instance 템플릿으로 사용해야합니다.
MIG(Managed Instance Group)에는 단일 영역에서 단일 엔티티로 관리할 수 있는 동일한 instance가 포함되어 있습니다. 관리되는 instance 그룹은 사전 예방적으로 사용 가능한 인스턴스(RUNING 상태)를 유지하여 애플리케이션의 고 가용성을 유지하세요. 프론트엔드 및 백엔드 instance에 관리 instance 그룹을 사용하여 자동 복구, 로드 밸런싱, 자동 스케일링 및 롤링 업데이트를 사용할 것입니다.
Create Instance Template from Source Instance
managed instance 그룹을 생성하려면 먼저 그룹의 기반이 될 instance 템플릿을 생성해야 합니다. instance 템플릿을 사용하면 새 VM instance를 생성할 때 사용할 시스템 유형, 부팅 디스크 이미지 또는 컨테이너 이미지, 네트워크 이미지, 네트워크 및 기타 인스턴스 속성을 정의할 수 있습니다. instance 템플릿을 사용하여 managed instance 그룹에 instance를 생성하거나 개별 instance를 생성하세요.
instance 템플릿을 만들기 위해서는 이전에 존재하는 생성한 instnace를 사용해야 합니다.
먼저 프론트엔드와 백엔드 instance를 멈추세요.
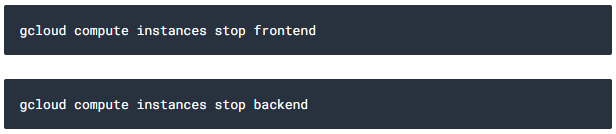
다음으로는 각 원본 instance에서 instance 템플릿을 생성하세요.
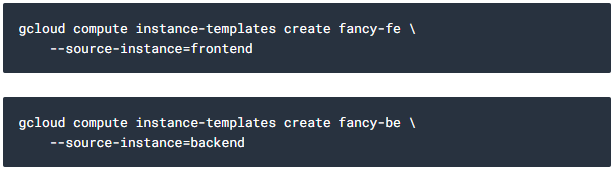
instance 템플릿이 생성된 것을 확인하시면 됩니다.

Output Example:

instance 템플릿을 생성한 후 백엔드 VM을 삭제하여 리소스 공간을 절약하세요.

일반적으로 프론트엔드 VM도 삭제할 수 있지만 나중에 instance 템플릿을 업데이트하는데 사용됩니다.
Create managed instance group
다음으로 프론트엔드와 백엔드 각각 하나씩, 두개의 managed instance 그룹을 생성하세요.

이러한 managed instance 그룹은 instance 템플릿을 사용하며 각 그룹 내에서 각각 시작할 두 instance에 대해 구성됩니다. instance 이름은 임의 문자가 추가된 지정된 기본 instance 이름에 따라 자동으로 지정됩니다.
애플리케이션의 경우 프론트엔드 마이크로 서비스는 포트 8080에서 실행되며 백엔드 마이크로 서비스는 포트 8081에서 실행됩니다. 주문의 경우 포트 8082에서 실행되며, 제품의 경우 포트 8082에서 실행됩니다.
비표준 포트이므로 명명된 포트를 지정하여 식별해야합니다. 명명된 포트는 서비스 이름과 실행 중인 포트를 나타내는 key:value 쌍 메타데이터 입니다. 명명된 포트를 instance 그룹에 할당할 수 있으며, 이는 그룹의 모든 instance에서 서비스를 사용할 수 있음을 나타내고 있습니다. 이 정보는 나중에 구성될 HTTP 로드 밸런싱 서비스에 의해 사용되어집니다.
Configure autohealing
애플리케이션 자체의 가용성을 개선하고 응답 중인지 확인하려면 관리되는 instance 그룹에 대한 자동 복구 정책을 구성하세요.
autohealing 정책은 애플리케이션 기반 health check에 의존하여 앱이 예상대로 응답하고 있는지 검증합니다. 앱이 응답하는지 확인하는 것은 단순히 instance가 기본 동작인 RUNING 상태인지 확인하는 것보다 더 정확합니다.
*로드 밸런싱 및 autohealing에 대한 별도의 health check가 사용됩니다.
로드 밸런싱 health check는 instance가 사용자 트래픽을 수신하는지 여부를 결정하기 때문에, 로드 밸런싱에 대한 health check가 보다 적극적으로 수행될 수 있습니다. 또한 응답하지 않는 instnace에 대해 빠르게 파악하여 트래픽을 리디렉션할 수 있습니다.
이와는 대조적으로 autohealing health check는 Compute Engine에서 장애가 발생한 instance를 능동적으로 교체하게 하므로 로드 밸런싱 health check보다 autohealing health check가 더 보수적이어야 합니다.
프론트엔드 및 백엔드에 대해 3회 연속 "unhealthy"를 반환하는 경우 instance를 복구하는 health check를 생성합니다.
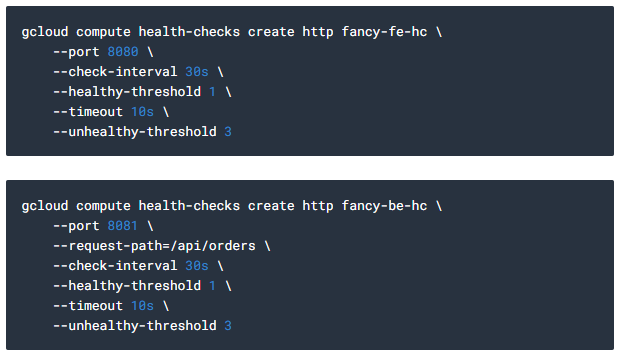
health check 시도가 포트 8080-8081의 마이크로 서비스에 연결할 수 있도록 허용하는 방화벽 규칙을 만드세요.

health check를 각 서비스에 적용합니다.
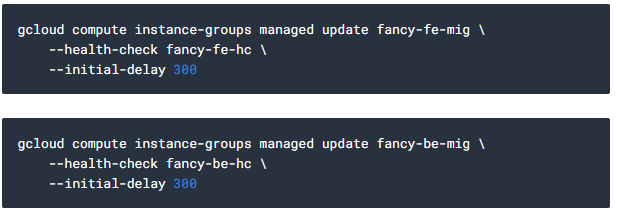
*autohealing 기능이 그룹 내 instance를 모니터링을 시작하는 데 15분이 걸릴 수 있습니다.
Create Load Balancers
managed instance 그룹을 보완하기 위해 HTTP(S) Load Balancer를 사용하여 프론트엔드 및 백엔드 마이크로 서비스에 트래픽을 제공할 수 있습니다. 그리고 매핑을 사용하여 pathing 규칙에 기반한 적절한 백엔드 서비스로 트래픽을 전송합니다. 이렇게 하면 모든 서비스에 대해 단일 로드 밸런싱 IP만 노출됩니다.
Create HTTP(S) Load Balancer
GCP는 여러 다른 타입의 로드 벨런서를 제공합니다. 이번 실습에서는 HTTP(S) Load Balancer를 사용하며 다음의 과정을 통해 설치 할 수 있습니다.
포워딩 규칙은 들어오는 요청들을 target HTTP 프록시로 전달합니다.
target HTTP 프록시는 각 요청을 URL 맵과 비교하여 확인후 요청에 적합한 백엔드 서비스를 결정합니다.
백엔드 서비스는 연결된 백엔드의 제공 용량, 영역, instance의 상태에 따라 각 request를 적절한 백엔드로 보냅니다. 각 백엔드 instance의 상태는 HTTP health check를 사용하여 확인됩니다. 백엔드 서비스가 HTTPS 또는 HTTP / 2 health check를 사용하도록 구성된 경우, request는 백엔드 instance로가는 도중에 암호화됩니다.
로드 벨런서와 instance 간의 세션은 HTTP, HTTPS 또는 HTTP / 2 프로토콜을 사용할 수 있습니다. HTTPS 또는 HTTP / 2를 사용하는 경우 백엔드 서비스의 각 instance에는 SSL 인증서가 있어야합니다.
SSL 인증서 복잡성을 피하기 위해 데모 목적으로 HTTPS 대신 HTTP를 사용하세요. 프로덕션의 경우 가능하면 암호화에 HTTPS를 사용하는 것이 좋습니다.
각 서비스에 대해 트래픽을 처리 할 수있는 instance를 결정하는 데 사용할 health check를 만듭니다.
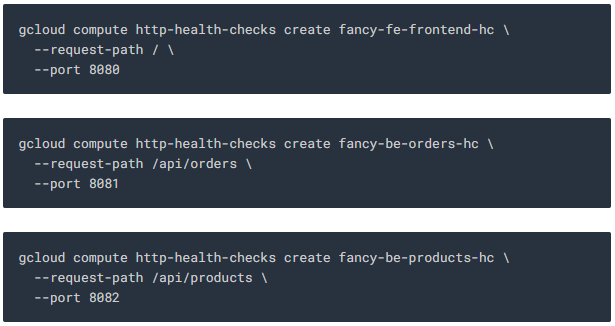
이러한 health check는 로드 밸런서 용이며, 로드 밸런서에서 보내는 트래픽 만 처리합니다. 관리 instance 그룹이 instance를 재생성하지 않습니다.
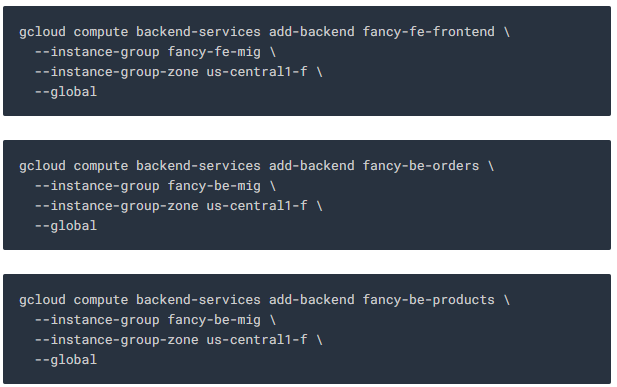
로드 벨런싱 된 트래픽의 target이되는 백엔드 서비스를 만듭니다. 백엔드 서비스는 health check 및 이름이 지정된 포트를 사용합니다.

로드벨런서의 백엔드 서비스를 추가합니다.
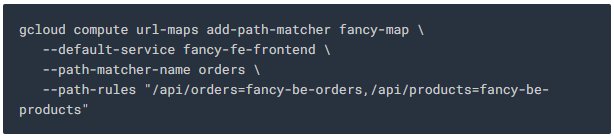
URL 맵을 만드세요. URL 맵은 어떤 URL이 어떤 백엔드 서비스로 연결되는지를 정의합니다.

/api/orders 및 /api/products 경로가 해당 서비스로 라우팅 될 수 있도록 path matcher를 생성합니다.
URL 맵에 연결되는 프록시를 만듭니다.

public IP 주소와 포트를 프록시에 연결하는 global forwarding rule을 만듭니다.

Update Configuration
이제 새 고정 IP 주소가 있으므로, 이전에 백엔드 instance를 가리키는 임시 주소 대신에 새 주소를 가리 키도록 프론트 엔드의 코드를 업데이트합니다.
Cloud Shell에서 .env 파일이 존재하는 react-app 폴더로 현재 경로를 변경합니다. .env 파일은 설정을 가지고 있습니다.

로드 밸런서의 IP 주소를 찾으세요.

Output example:

Cloud Shell 편집기로 돌아가서 Load Balancer의 public IP를 가리 키도록 .env 파일을 다시 편집합니다. [LB_IP]는 위에서 결정된 백엔드 instance의 외부 IP 주소를 나타냅니다.

로드 밸런서가 전달을 처리하도록 구성 되었기 때문에 새 주소에서 포트가 제거됩니다.
파일을 저장하세요.
프론트 엔드 코드를 업데이트하는 react-app을 다시 빌드합니다.

애플리케이션 코드를 버킷에 복사합니다.

Update the frontend instances
이제 새 코드와 환경설정이 있으므로 managed instance 그룹 내의 프론트 엔드 instance가 새 코드를 가져 오도록합니다. instance가 시작시 코드를 가져 오므로 롤링 재시작 명령을 실행할 수 있습니다.

이 롤링 교체 예에서는 --max-unavailable 매개 변수를 통해 모든 머신을 즉시 교체 할 수 있음을 구체적으로 설명합니다. 이 매개 변수가 없으면 명령은 가용성을 보장하기 위해 다른 인스턴스를 다시 시작하는 동안 인스턴스를 활성 상태로 유지합니다. 테스트 목적으로 속도를 위해 모두 즉시 교체하도록 지정합니다.
Test the website
rolling-action replace 명령어를 실행 한 후 약 30 초 동안 기다립니다. instnace를 처리 할 시간을 준 다음 instance가 목록에 나타날 때까지 managed instance 그룹의 상태를 확인합니다.

목록에 항목이 나타나면 Ctrl + C를 눌러 watch 명령을 종료합니다.
다음을 실행하여 서비스가 HEALTHY로 나열되는지 확인합니다.

두 서비스가 HEALTHY로 표시 될 때까지 기다리세요.
Output example:
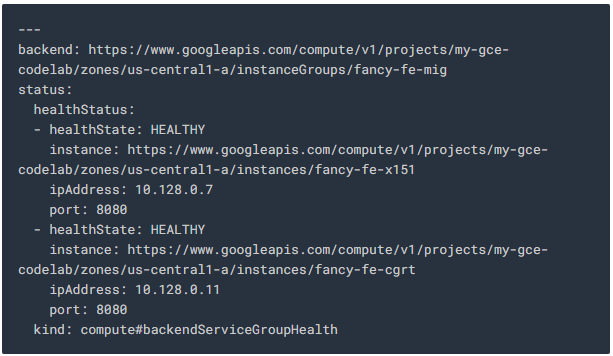
한 instance에 문제가 발생하고 UNHEALTHY인 경우 자동으로 복구해야합니다. 그러므로 자동 복구가 일어날 때까지 기다리셔야합니다. 모든 instance가 기다린 후에도 HEALTHY 상태가되지 않으면 포트 8080에서 액세스하는 프론트 엔드 instance 설정에 문제가 있는 것입니다. 포트 8080에서 직접 instance를 찾아 테스트해야 합니다.
두 항목이 모두 목록에 HEALTHY로 나타나면 Ctrl + C를 눌러 watch 명령을 종료합니다.
http://[LB_IP]를 통해 애플리케이션에 액세스 할 수 있습니다. 여기서 [LB_IP]는로드 밸런서에 지정된 IP_ADDRESS이며 다음 명령을 사용하여 찾을 수 있습니다.
gcloud compute forwarding-rules list --global
Scaling Compute Engine
지금까지 각각 2 개의 instance가 있는 2 개의 managed instance 그룹을 만들었습니다. 이 환경설정은 완전히 작동하지만 부하에 관계없이 정적으로 구성되어 있습니다. 그래서 다음으로 사용률에 따라 autoscaling policy를 만들어 각 managed instance 그룹을 자동으로 확장합니다.
Automatically Resize by Utilization
autoscaling policy를 생성하려면 다음을 실행하세요.
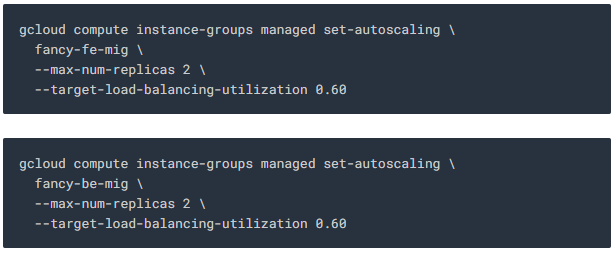
위 명령어는 사용률이 60 %를 초과하면 instance를 자동으로 추가하고, 로드 벨런서가 사용률이 60 % 미만이면 instance를 제거하는 managed instance 그룹에 autoscaler를 만듭니다.
Enable Content Delivery Network
scaling에 도움이되는 또 다른 기능은 Content Delivery Network 서비스를 활성화하여 프론트 엔드에 캐싱을 제공하는 것입니다.
프론트 엔드 서비스에 다음의 명령어를 실행하면 됩니다.

사용자가 HTTP(S) 로드 벨런서에서 콘텐츠를 요청하면, 요청이 Google Front End(GFE)에 도착하여 먼저 Cloud CDN 캐시에서 사용자의 요청에 대한 응답을 찾습니다. GFE가 캐시 된 응답을 찾으면 GFE는 캐시 된 응답을 사용자에게 보냅니다. 이를 cache hit 이라고합니다.
GFE가 요청에 대해 캐시 된 응답을 찾을 수없는 경우, GFE는 백엔드에 직접 요청합니다. 이 요청에 대한 응답이 캐시 가능한 경우 GFE는 후속 요청에 캐시를 사용할 수 있도록 응답을 Cloud CDN 캐시에 저장합니다.
Update the website
Updating Instance Template
기존 instance 템플릿은 편집 할 수 없습니다. 그러나 instance가 stateless이고 모든 구성이 startup scripts를 통해 수행되므로 템플릿 설정을 변경하려는 경우에만 instance 템플릿을 변경하면됩니다. 이제 더 큰 머신 유형을 사용하기 위해 간단한 변경을 수행하고 이를 push합니다.
instance 템플릿의 기반 역할을하는 프론트 엔드 instance를 업데이트합니다. 업데이트 중에, instance 템플릿 이미지의 업데이트 된 버전에 파일을 배치 한 다음, instance 템플릿을 업데이트합니다. 그리고 새 템플릿을 출시 한 다음 managed instance 그룹 instance에 파일이 있는지 확인합니다.
이제 n1-standard-1 머신 유형에서 4 개의 vCPU 및 3840MiB RAM이있는 커스텀 머신 유형으로 전환하여 instance 템플릿의 머신 유형을 수정합니다.
다음 명령어를 실행하여 프론트 엔드 instance의 머신 유형을 수정합니다.

새로운 instance 템플릿을 생성합니다.

업데이트 된 instance 템플릿을 managed instance 그룹에서 시작합니다.

30 초 동안 기다린 후 다음을 실행하여 업데이트 상태를 모니터링합니다.

다음 조건의 instance가 1 개 이상있는 경우 :

다음 명령에서 사용하기 위해 나열된 machines 중 하나의 이름을 복사하세요.
Ctrl + C를 눌러 감시 프로세스를 종료합니다.
다음을 실행하여 가상 머신이 새 머신 유형 (custom-4-3840)을 사용하고 있는지 확인합니다. 여기서 [VM_NAME]은 새로 생성 된 instance입니다.

Expected example output:

Make changes to the website
시나리오 : 마케팅 팀이 사이트의 홈페이지 변경을 요청했습니다. 그들은 당신의 회사가 누구이고 당신이 실제로 무엇을 판매하는지에 대해 더 많은 정보를 제공해야한다고 생각합니다.
작업 : 개발자 중 한 명이 이미 index.js.new라는 파일 이름으로 변경 사항을 만든 것 같습니다. 이 파일을 index.js에 복사하면 변경 사항이 반영됩니다. 아래 지침에 따라 적절하게 변경하시면 됩니다.
다음 명령을 실행하여 업데이트 된 파일을 올바른 파일 이름으로 복사하세요.

파일 내용을 인쇄하여 변경 사항을 확인합니다.

결과 코드는 다음과 같습니다.
/*
Copyright 2019 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
import React from "react";
import { makeStyles } from "@material-ui/core/styles";
import Paper from "@material-ui/core/Paper";
import Typography from "@material-ui/core/Typography";
const useStyles = makeStyles(theme => ({
root: {
flexGrow: 1
},
paper: {
width: "800px",
margin: "0 auto",
padding: theme.spacing(3, 2)
}
}));
export default function Home() {
const classes = useStyles();
return (
<div className={classes.root}>
<Paper className={classes.paper}>
<Typography variant="h5">
Fancy Fashion & Style Online
</Typography>
<br />
<Typography variant="body1">
Tired of mainstream fashion ideas, popular trends and societal norms?
This line of lifestyle products will help you catch up with the Fancy trend and express your personal style.
Start shopping Fancy items now!
</Typography>
</Paper>
</div>
);
}React 구성 요소를 업데이트했지만 정적 파일을 생성하려면 React 앱을 빌드해야합니다.
다음 명령을 실행하여 React 앱을 빌드하고 monolith 공용 디렉토리에 복사하세요.

그런 다음이 코드를 버킷에 다시 푸시합니다.

Push changes with rolling replacements
이제 모든 인스턴스를 강제로 교체하여 업데이트를 가져옵니다.

이 롤링 교체 예에서는 --max-unavailable 매개 변수를 통해 모든 머신을 즉시 교체 할 수 있음을 구체적으로 설명합니다. 이 매개 변수가 없으면 명령은 다른 instance를 대체하면서 instance를 활성 상태로 유지합니다. 테스트 목적으로 속도를 위해 모두 즉시 교체하도록 지정합니다. 프로덕션에서 버퍼를 남겨두면 웹 사이트가 업데이트하는 동안 웹 사이트를 계속 제공 할 수 있습니다.
rolling-action replace 명령어를 실행 한 후 약 30 초 동안 기다리면서 instance를 처리 할 시간을 줍니다. 그리고 instance가 목록에 나타날 때까지 managed instance 그룹의 상태를 확인합니다.

목록에 항목이 나타나면 Ctrl + C를 눌러 watch 명령을 종료합니다.
다음을 실행하여 서비스가 HEALTHY로 나열되는지 확인합니다.

두 서비스가 모두 HEALTHY로 나타날때까지 잠시 기다리세요.
Example output:
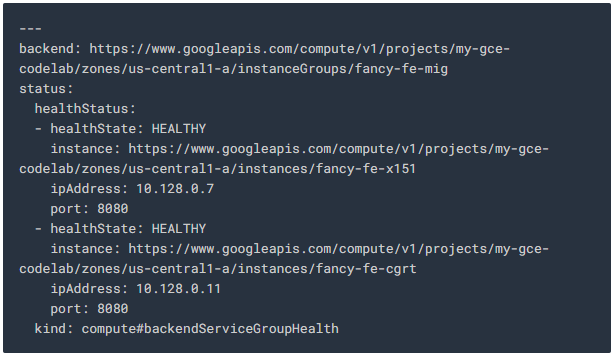
목록에 항목이 나타나면 Ctrl + C를 눌러 watch 명령을 종료합니다.
http://[LB_IP]를 통해 웹 사이트로 이동합니다. 여기서 [LB_IP]는 Load Balancer에 지정된 IP_ADDRESS이며 다음 명령으로 찾을 수 있습니다.

이제 새 웹 사이트 변경 사항이 표시됩니다.
Simulate Failure
health check가 작동하는지 확인하려면 instance에 로그인하고 서비스를 중지하세요.
인스턴스 이름을 찾으려면 다음을 실행하세요.

instance 이름을 복사 한 후 다음을 실행하여 instance에 셸을 보호합니다. 여기서 INSTANCE_NAME은 목록의 instance 중 하나입니다.

확인하려면 "y"를 입력하고 암호를 사용하지 않으려면 Enter 키를 두 번 누릅니다.
instance 내에서 supervisorctl을 사용하여 애플리케이션을 중지합니다.

instance를 종료합니다.

repair operations을 모니터링합니다.

Output:
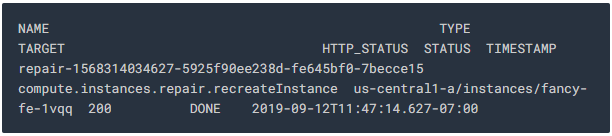
managed instance 그룹이 instance를 다시 생성하여 복구합니다.
콘솔을 통해 모니터링 할 수도 있습니다. Navigation menu > Compute Engine> VM instances로 이동합니다.
이상으로 Compute Engine을 사용한 웹 페이지 빌드하는 실습을 마치도록 하겠습니다! 수고하셨어요~