티스토리 뷰
Lecture 3 : Planning by Dynamic Programming
-Introduction
-Policy Evaluation
-Iterative Policy Evaluation
-Example: Small Gridworld
-Policy Iteration
-Example: Jack's Car Rental
-Policy Improvement
-Extensions to Policy Iteration
-Value Iteration
-Value Iteration in MDPs
-Summary of DP Algorithms
-Extensions to Dynamic Programming
-Asynchronous Dynamic Programming
-Full-width and sample backups
-Approximate Dynamic Programming
-Contraction Mapping
What is dynamic Programming?
다이나믹 프로그램은 큰문제를 작은 부분 문제로 나누고, 그 부분 문제들에 대한 solution을 구합니다. 그리고 부분 문제들을 모으면서 본 문제를 해결합니다.

Requirements for Dynamic Programming
dynamic programming이 쓰이기 위해서는 다음 2가지가 필요합니다. 먼저, Sub structure가 있어야합니다. 즉 전체의 문제가 부분 문제로 나뉠 수있어야 합니다. 마지막으로는 먼저 구한 부분 문제가 cache로 작용하여 다른 문제를 풀때 적용될 수있어야합니다. MDP는 위 조건을 만족합니다.왜냐하면 Bellman equation은 재귀함수로 분해할 수 있기 때문입니다. 현재 가정은 environment를 다 알고 있을 때 최적의 policy를 찾는게 목표입니다.

Planning by Dynamic Programming
Dynamic Programming은 MDP에 대한 모든 지식을 알고있다고 가정합니다. planning은 model을 알때 최적의 policy를 찾습니다. 풀어야하는 문제가 2가지가 있습니다. 하나는 prediction 나머지는 control입니다. prediction은 value function을 학습합니다. control은 policy를 찾습니다.

Other Applications of Dynamic Programing
Dynamic Programing은 인공지능에만 한정되는 도메인이 아니라 다양한 곳에 쓰입니다.

Iterative Policy Evaluation
Policy를 평가한다는 것은 어떤 policy를 따라갔을때 Return을 얼마나 받느냐를 안다는 것은 value function을 안다는 것입니다. backup은 cache와 같습니다. 임시 저장소라고 보시면 됩니다(메모리에). 또한 policy evalution을 하기위해서는 synchronous backups 방법을 사용합니다. 방법의 자세한 부분은 아래의 슬라이드에 나와있습니다. 또한 synchronous backups 방법을 사용하면 v1 -> v2 -> ... -> v파이 형식으로 됩니다. 즉, v파이에 수렴합니다.

Iterative Policy Evaluation(2)
매 iteration 마다 벨만 방정식을 반복합니다. v k+1(s) <-s 는 아래의 4개의 state들의 값들을 이용해서 업데이트합니다. 우리가 흔이 알고있는 알고리즘의 dynamic programing을 재귀형식으로 푸는 방법처럼 비슷해보입니다.

Evaluating a Random Policy in the Small Gridworld
한번 움직일때마다 reward는 -1입니다. terminal state는 grid에 표시된걸 보시면 2개이지만 하나의 state라고 합니다.

Iterative Policy Evaluation in Small Gridworld
처음에는 0으로 초기화를 했습니다. 감마는 1입니다. k가 무한대로 가서 종료되면 하나의 iteration이 끝나는겁니다.

Iterative Policy Evaluation in Small Gridworld(2)
iterative 하게 벨만 expectation equation을 적용해서 값을 찾아 나갑니다. policy를 평가한 곳에 greedy하게 움직여도 더 나은 policy를 찾을 수 있다고 합니다.

How to Improve a Policy
먼저 policy를 평가하고(평가한다는 것은 value function을 찾는다는 것입니다), 그 value function에 대해서 greedy하게 움직이는 새로운 policy를 만들면 점점 optimal policy 파이로 수렴합니다.

Policy Iteration
policy iteration이란 evaluation과 improvement가 한 세트가 되어 반복하여 진행하는 것을 말합니다.

Jack's Car Rental

Policy Iteration in Jack's Car Rental

Policy Improvement
정말 policy improvement를 하면 더 나은 fucntion이 되는지에 대한 증명입니다.

Policy Improvement(2)

Modified Policy Iteration
이전의 Iterative PolicyEvaluation in Small Gridworld에서 k = 3일때 이미 greedy하게 갈 수있는 policy가 만들어지는데, 굳이 v 파이까지 iteration을 반복해야 하는가? 일찍 끝내면 안되나? 그렇게 해도 된다고 합니다.

Generalised Policy Iteration

Principle of Optimality
optimal policy는 두 요소로 나뉠 수 있습니다. optimal action과 그 optimal policy를 따른 state입니다.

Deterministic Value Iteration
s'의 solution을 알면 s에서의 solution도 당연히 알 수 있습니다.아래의 식은 벨만 optimality equation입니다. 그리고 policy가 없어도 계산되는 식입니다. 여기서 맥스는 R에만 해당되는게 아닌 전체를 포함하고 있습니다.

Example: Shortest Path

Value Iteration

Value Iteration(2)
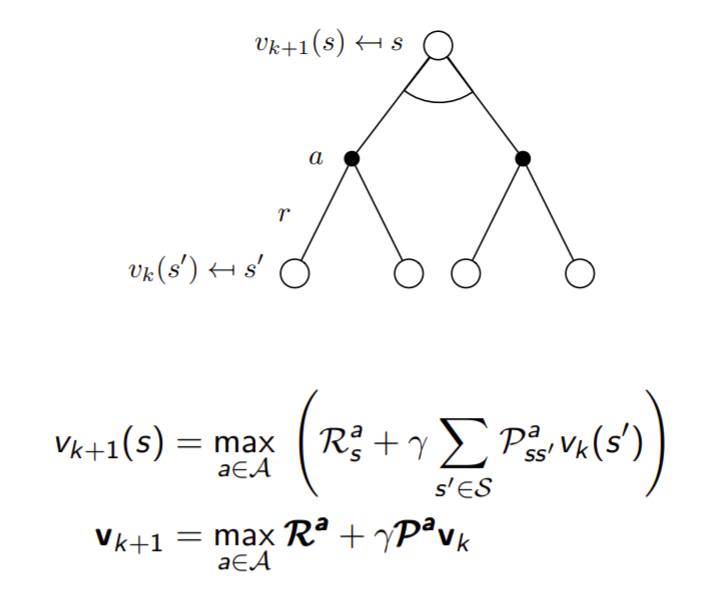
Synchronous Dynamic Programming Algorithms
synchronous라는 뜻은 한 타이밍에 모든 state들을 다 업데이트 합니다.

Asynchronous Dynamic Programming
한번에 모든 state가 업데이트 하지않고 부분적으로 하거나, 순서를 바꾸어서도 가능합니다. 이러한 방법론은 computation을 획기적으로 줄일 수 있습니다.

Asynchronous Dynamic Programing

In-Place Dynamic Programming
이 부분은 사실 코딩 테크닉에 더 가깝습니다. state를 저장하는 table은 2개가 있어야합니다. 한가지는 이전 state들을 저장하는 table, 다른 한가지는 다음 state들을 저장하는 테이블입니다. 왜냐하면 다음 state들은 이전 state들의 table을 가지고 계산되기 때문입니다. 하지만 In Place는 한가지 table만 가지고 있습니다. 어떻게 가능하냐면, 다음 state들은 이전state정보를 가지고 계산됩니다. 하지만 In-Place는 갱신된 state정보를 그대로 쓰기때문에 하나의 table만 필요합니다. 증명된 사실이라고 합니다.

Prioritised Sweeping
각 state별 value를 업데이트 할때, 중요한 state먼저 합니다. 벨만 error가 큰 것이 중요한것입니다.

Real-Time Dynamic Program
state space가 굉장히 넓습니다. 하지만 agent가 가는 곳은 한정적일때, agent 가 움직이는 곳 먼저 업데이트합니다.

Full-Width Backups
DP는 애초에 Full-width backups를 씁니다. 하지만 큰 문제에서는 모든걸 다 볼 수 없습니다. 그래서 위와 같은 문제들은 차원의 저주를 따르게됩니다. state가 늘어날수록 exponentially하게 늘어납니다.

Sample Backup
State가 많아져도 고정된 비용으로 backup을 할 수 있습니다. 또한 model free 상태에서도 가능합니다. 현재까지 저희는 model based RL을 하고있습니다. 내가 어느 state에 있을 때 어떤 action을 하면 어디 도착할지 다 아는 상태입니다. 모델에 대한 충분한 정보를 알고있으며, 그 상황에서 control문제 혹은 prediction 문제를 진행하고 있었습니다. 한편 model free는 내가 action을 해도 어디 도착할지 모릅니다. 그랬을때 action하나를 sampling 합니다.
