티스토리 뷰
Lecture 2 : Markov Decision Process
-Markov Processes
-Introduction
-Markov Property
-Markov Chains
-MRP
-Markov Reward Processes
-MRP
-Return
-Value Function
-Bellman Equation
-Markov Decision Processes
-MDP
-Policies
-Value Functions
-Bellman Expectation Equation
-Optimal Value Functions
-Bellman Optimality Equation
Introduction to MDPs
전에 state에서 배운 내용의 연장선입니다. 거의 모든 강화학습의 문제는 MDP로 만들 수 있습니다. 즉 MDP는 강화학습 문제를 formalize하게 하는것입니다. 여기서 MDP의 조건이 다시한번 나오는데 fully observable합니다. 즉, agent의 state와 environment의 state가 같습니다.

Markov Property
전에 설명하였던 Markov property에 대해 복습합니다. state는 history에 있는 모든 관련된 정보들을 가지고 있습니다.(state는 history에 대한 함수입니다.) 그리고 state는 미래에 대한 충분한 통계입니다.

State Transition Matrix
state transition probability(s에서 s'으로 갈 확률)는 action없이 아래와 같이 정의됩니다.(state들은 n개까지 있으며 discrete하게 떨어져 있습니다.

Markov Process
S는 states들의 유한집합입니다. 그리고 다음으로 필요한 것은 state들의 전이확률이 필요합니다. Markov chain은 이산 시간 확률 과정입니다.(여기서 확률 과정이란 확률 분포를 가진 랜덤 변수가 일정한 시간 간격으로 값을 발생시키는 것을 모델링합니다.) 또한 시간에 따른 계의 상태의 변화를 나타냅니다. 매 시간마다 계는 상태를 바꾸거나 같은 상태를 유지합니다. 상태의 변화를 전이라고합니다. Markov property는 과거와 현재 상태가 주어졌을 때의 미래 상태의 조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결정된다는 것을 뜻합니다. 위 정의는 지난 강의시간때 했었습니다. state와 probability로 표현가능합니다.

Example : Student Markov Chain
state는 총 7개이며, state들의 전이 확률은 화살표로 표시되어 있습니다. sleep은 terminal state입니다. 다시 나가는 길이 없어요..

Example : Student Markov Chain Episodes
어느 state에서 시작해서 terminal state인 Sleep까지 가는 것을 Episode라고 합니다. 아래에 제시된 4가지 Episode들을 볼 수 있습니다. 해당 Episode는 Markov process에서 샘플링 한것입니다.

Example : Student Markov Chain Transition Matrix
아래와 같이 matrix형태로 표현가능합니다.

Markov Reward Process
이제는 Markov Process에서 Markov Reward Process로 넘어갑니다. Markov Process에서 R과 감마가 추가되었습니다. S는 state의 집합, P는 state transition probability matrix, R은 reward fucntion, r(감마)는 discount factor입니다.

Example : Student MRP
빨간색 글자에 집중합니다. R은 reward로 각각에 표시된 state에 있을때 얻거나 잃는 행동을 합니다. 예를 들어 class1은 -2점이 깎입니다. 엣지(action이라고 말할 수 있습니다)에다가 reward를 줄 수는 없습니다. 이것은 state에 대한 것이지 action에 대한 reward가 아니기 때문입니다.

Return
강화학습은 return을 Maximize하는게 목표입니다.(agent의 목표는 value function의 최대값을 구하는 것입니다.) 감가상각(감마)을 해서 모두 더해줍니다. 감마가 0에 가까우면 근시안적(myopic)이며 순간적인 값만 중요합니다. 1에 가까울 수록 멀리보는(far-sighted) 경향을 가집니다.

Why discount?
솔직한 이유는 수렴성이 수학적 이유에서 편리합니다. 마지막 줄을 보시면, 모든 sequence들이 terminal state로 갈 수 있으면 감마를 때로는 1로 쓸 수 있다고도 합니다. 무한루프가 발생하지 않아서 가능한거 같습니다. 그리고 문제에 따라서 discount가 필요한 경우도 있고 아닌경우도 있다고 합니다.

Value Function
Value Function은 Return의 기대값입니다. 여기서 Gt는 Return입니다 그리고 확률변수입니다. 왜 확률변수이냐면, sequence에 따라 return 값이 다르기 때문입니다.(Return들의 평균)

Example : Student MRP Returns

Example : State-Value Function for Student MRP(1)
감마가 0일때 (discount가 없을때) state value function을 각 state 마다 구해놨습니다. 구하는 방법은 나중에 나옵니다.

Example: State-Value Function for Student MRP(2)

Example: State-Value Function for Student MRP(3)
감마가 1일 땐 앞에서 배웠던 far-sighted합니다.

Bellman Equation for MRPs
value function이 학습되는건 전부 Bellman Equation에 의해서 진행됩니다. Bellman Equation은 s에서의 value에서 한 step 더 가서 봅니다. 그리고 그것에 다음 state의 value의 합과 같습니다. 마지막 식에서 G t+1의 값이 v이기 때문에 다음과 같이 쓸 수 있습니다. low of expectation?에 의해 expectation이 안에 들어갈 수있습니다.

Bellman Equation for MRPs(2)
v(s)는 재귀함수처럼 보입니다. (여기서 나오는 R과 P는 모두 model의 예측치입니다.)즉, value function은 model의 예측치로 설명될 수 있습니다. 밑의 식을 해석해보자면, s에 대한 value function = R t+1 에서 얻을 수 있는 기대값 + 감마 x 시그마(s에서 s'으로 가는 전이확률 x s'에 대한 value function입니다.

Example: Bellman Equation for Student MRP
닭이먼저냐 달걀이 먼저냐... terminal에서 시작해야되지 않을까. 각 노드 안에 있는 값들을 v(s)(value function)의 값들입니다. Rs는 각 노드에서 얻을 수 있는 reward입니다. 예를들어 하단에 R = -2 라고 써져있는 노드도 보입니다.

Bellman Equation in Matrix Form
Bellma equation은 다음과 같이 matrix로 표현될 수 있습니다.

Solving the Bellman Equation
감마와 P(예측)와 R(예측)을 알면 value function을 구할 수 있습니다. 그런데 시간복잡도가 O(n^3)이므로 Direct solution에서는 작은 MRPs만 가능합니다. 비용이 많이 드므로 iterative한 방법을 많이 사용합니다.

Markov Decision Process
Markov Reward Process에서 action이 추가됐습니다.또한 environment의 state는 Markov합니다.

Example : Student MDP
각 state의 이름이 사라졌습니다. 이제 더이상 이름은 중요하지 않은것입니다. action을 할때 reward를 받습니다. MRP는 state마다 reward가 있었는데 MDP는 그렇지 않습니다. 또한 action을 하면 확률적으로 어떤 state에 가게됩니다. 즉, action이 가지고 있는 어떠한 전이확률에 따라서 움직이게 됩니다.
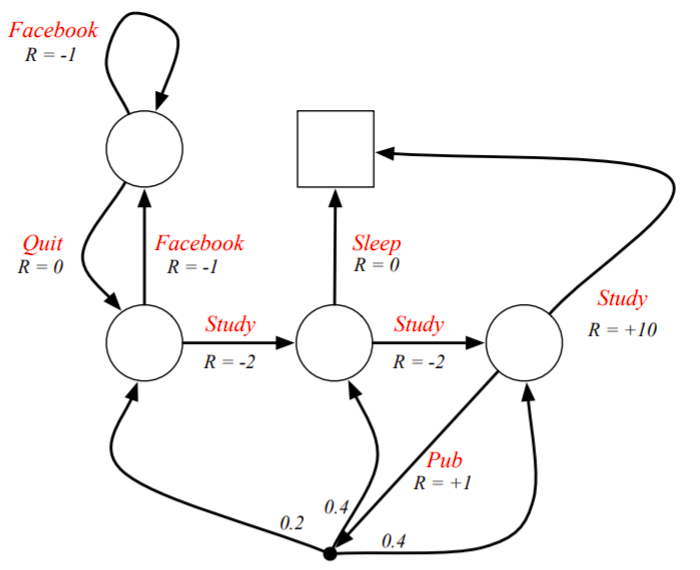
Policies(1)
전의 MRP에서는 확률분포에 따라 내가 현재 state에서 다음 state로 갈지 정해졌는데, MDP는 action하는 것에 따라 다음 state가 달라집니다. 그러므로 내가 어떤 policy를 받고 할지가 중요합니다. !!MRP는 environment에서 사용하는 것이며, MDP는 agent가 사용합니다. (action이 있기 때문에?)

policy(2)
MDP에서 임의의 policy 파이를 가지고 움직일때,P와 R의 정의가 다음과 같이 됩니다.

Value Function
2가지의 value function이 있습니다. 첫번째는 state-value function이고 두번째는 action-value fiunction입니다. input이 state만 들어가면 state-value function이며, input에 state와 action이 들어가면 action-value function입니다. 딥큐 러닝은 action-value fucntion을 학습시킨 것입니다.

Example : State-value Function for Student MDP
여기서의 policy는 모든 state에서 각action의 확률이 1/2입니다.

Bellman Expectation Equaion

Bellman Expectation Equation for V파이

Bellman Expectation Equation for Q파이

Bellman Expectation Equation for V파이(2)

Bellman Expectation Equation for q파이(2)

Example : Expectation Equation in Student MDP

Bellman Expectation Equation(Matrix Form)

Optimal Value Function
*는 모든 policy를 따랐을 경우 그중 optimal한 value function입니다. 그리고 우리는 optimal value를 알때 MDP문제를 풀었다라고도 합니다.

Example : Optimal Value Function for Student MDP
감마가 1일때 optimal value function을 나타낸것입니다. 빨간색은 optimal value입니다.

Example : Optimal Action-Value Function for Student MDP
다음 빨간색은 action-value function의 값입니다.

Optimal Policy
두 policy가 있을때 어떤게 더 나은지 비교해야하므로 partial ordering을 합니다. partial ordering 이란 어떤 policy 두개를 비교할때 항상 비교할 수 있는건 아닙니다. 대신 어떤 경우에 더 낫다고 하는 상황은 존재합니다. 그래서 아래의 식과 같이 나타냅니다. 다음으로 박스 안의 설명을 보겠습니다. 모든 MDP문제에 대해 optimal policy가 존재한다고 합니다. 참고로 optimal policy는 여러개일 수 도 있습니다. 그래서 all optimal policies라고 표현합니다.

Finding an Optimal Policy
optimal policy는 q*를 아는 순간 무조건 하나는 찾아집니다. 아래에서 deterministic이라고 되어있는데 확률적인 stocastic과는 다른 0과 1로 나뉘는 것을 deterministic이라고 합니다. q*를 알면 문제를 푼거라고 말할 수 있습니다.(1장 policy 부분에서 다시 설명되어 있습니다.)

Example : Optimal Policy for Student MDP
빨간색은 optimal policy입니다.

Bellman Optimality Equation for V*

Bellman Optimality Equation for Q*

Bellman Optimality Equation for V* (2)
max를 사용하기 때문에 liner하지 않습니다. 이 부분이 Bellman Expectation Equation과 다른점입니다.
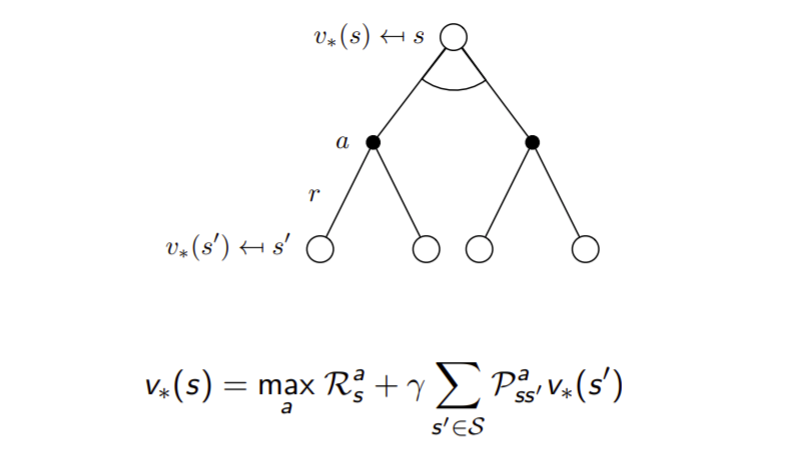
Bellman Optimality Equation for Q* (2)

Example : Bellman Optimality Equation in Student MDP

Solving the Bellman Optimality Equation
Bellman Optimality Equation은 non-linear이기 때문에(max 때문에) closed form으로 풀 수 없습니다.그래서 iterative한 solution방법들이 있는데 다음과 같습니다.
