티스토리 뷰
구글 딥마인드의 David Silver 교수님의 수업 자료를 바탕으로 정리한 RL강의입니다.
목차에 하나씩 추가하며 진행할 계획입니다.
Lecture 1 : Introduction to Reinforcement Learning
-About RL
-The RL Problem
-Reward
-Environment
-State
-Inside An RL Agent
-Problems within RL
Machine Learning
기계학습에는 supervised learning, unsupervised learning, reinforcement learning 세가지가 존재합니다. 밑에 그림에서 공집합의 결과가 ML로 되있는 것처럼 보이는데, 사실 전체 큰 원이 ML이라고 보시면 됩니다. 각자 학습 방법에는 공통적인 방법과 서로 다은 방법이 있습니다.

강화학습에는 다른 학습과 다른 특징 들이 있습니다. supervisor가 없다는 것은 답인지 오답인지 알려주는 agent가 없다는 것입니다. 그러므로, agent가 reward를 받으면서 학습을 진행합니다.(reward를 maximize하는것을 목표로합니다.) 또한, feedback은 즉각적으로 반영되지 않습니다. 그리고 시간적인 부분의 영향이 있기 때문에, 데이터의 순서도 중요합니다. 마지막으로 agent의 행동이 다음에 받게될 데이터에 영향을 줍니다. 그러므로 어떤 데이터를 어떻게 받을지도 학습과정에서 중요하게 작용합니다.(어떻게 fitting 하느냐에 따라 받는 데이터가 달라집니다.)

다음으로 강화학습의 예시입니다.

Reward
Reward는 agent가 step t에 따라서 얼마나 잘 하고 있느냐를 나타내는 지표입니다. 여기서 Rt에대한 설명을 드리자면 R은 reward를, t는 time step을 의미합니다. 즉, time step에 따른 reward는 scalar feedback입니다. 앞으로 용어들의 정의에 대해서 많이 나올텐데 그중 중요한 Reward에 대한 정의는 다음과 같습니다. "모든 목표는 기대하는 축척된 보상들의 값을 최대화 시키는 것으로 설명될 수 있습니다." (또한 이것은 agent의 활동 목표입니다.)그리고 RL은 이러한 reward hypothesis를 바탕으로 학습을 진행합니다.

Enamples of Rewards

Sequential Decision Making
Sequential Decision Making이 중요합니다. 한순간에만 잘하는 것이 아닌 연속적으로 순서에 맞게 Decision을 해야합니다. 그래서, 모두 그리디 방식으로 하기 보다는 long term reward가 더 좋은 효과를 만들어 낼 수 있습니다. 목표는 미래의 보상을 최대화하는 action들을 선택해야 합니다.

Agent and Environment

action은 행동의 단위입니다. 그 action이 environment에 영향을 끼치면 environment는 두가지를 output으로 내놓습니다. reward와 observation입니다. observation은 agent가 한 action으로 인해 environment가 바뀐 현황을 agent에게 알려줍니다. 아래와 같은 방식으로 agent와 environment가 상호작용합니다.
그림은 agent와 environment가 주고 받는 상호작용을 나타냅니다.

history and state
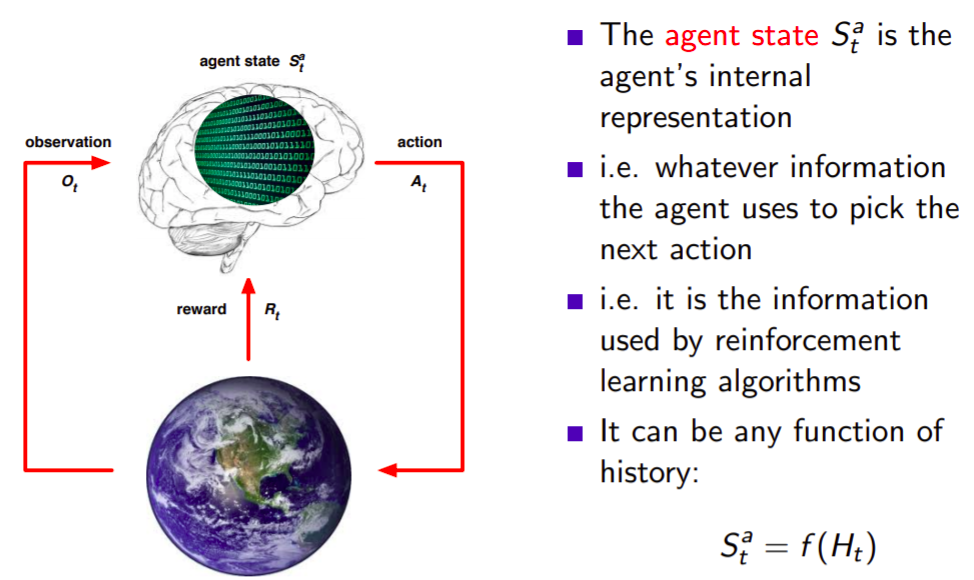
History and State, history는 agent와 environment가 한것들(obervations, actions, rewards)을 기록하는 것입니다. agent와 environment는 history를 보고 자신들이 행할 것들을 판단하여 실행합니다. state는 다음에 뭘할지 결정하기 위해서 쓰이는 정보들입니다. 즉, state는 history의 함수입니다. St = f(Ht). 히스토리 안에있는 정보를 가공해서 state를 만듭니다.

environment state
먼저 environment의 state입니다. environment state는 agent에게 보이지 않습니다. 만약 보이더라도 관련 없는 정보들도 포함해있어서 비효율적입니다.

environment state의 이해를 돕기위해 다음을 먼저 설명합니다. 플레이스테이션이나 xbox 같은 콘솔을 environment라고 할 수 있습니다. 해당 environment에는 observation 뿐만 아니라 다양한 정보를 담은 state들이 많이 있습니다. 하지만 이 invironment state를 전부 사용하는 것이 아닌 observation만 사용합니다.
Agent state
내가 다음 action을 해야할때 쓰이는 정보들(state)을 agent state라고 합니다. 바로 사용할 수도 있으며 가공할 수도 있습니다.
Information state
state를 markov 관점에서도 생각해 볼 수 있습니다. state가 markov하다는 것은, 현재 state를 결정할때 이전 tick만 의존하면 된다는 것입니다. 아래의 Definition의 정의를 보면 더 쉽게 이해할 수 있습니다. S(t+1)은 바로 이전 state인 S(t)만 영향을 미칩니다. RL은 markov 정의아래 행동합니다.

Rat example
다음과 같이 3개의 신호가 있습니다. 1번 신호 : 전구 켜기, 2번 신호 : 레버 당기기, 3번 신호 : 종 울리기입니다. 1번 sequence는 전구 2번 울리고, 레버를 당기로 종을 울리면 전기충격을 받습니다. 2번 sequence는 종을 울리고 전구를 키고 레버를 2번 당기면 치즈가 나옵니다. 이러한 상황을 바탕으로 3번 seqence에서는 어떤 결과가 나올까요? 이건 state를 어떻게 정의하느냐에 따라 결과가 달라집니다. 최근 3개의 item으로 상황을 판단한다고 하면 1번 sequence와 같은 상황이여서 전기 충격의 결과가 나온다고 생각할 수 있습니다. 다음으로는 전구, 종, 레버의 갯수로 state를 판단한다고 한다면, 1번 seqence는 2, 1, 1입니다. 2번 seqence는 1, 1, 2입니다. 그리고 해석하고자 하는 3번째 seqeunce는 1, 1, 2 이므로 결과적으로 치즈가 나온다고 생각 될 수 있습니다.
이 예시를 보면 state는 history의 정보들을 가공해서 내가 정의하는 상황에 맞게 사용할 수 있습니다. 또 어떻게 정의하느냐에 따라 성능이 달라질 수도 있습니다.

Fully Observable Environments
environment의 state를 볼 수 있는 것을 fully observable environments 하다고 합니다. 이때는 observation의 state와 agent의 state와 environment 의 state가 같은 상황입니다. 이것을 MDP(Markov decision process)라고 이야기합니다. 2장에서 자세히 이야기 합니다.

Partially Observable Environment
이때는 agent의 state와 environment의 state가 같지 않습니다. 예를 들어 로봇이 움직일때 머리에 있는 카메라를 통해서 시야를 확보하는 데 앞에 있는 것을 보여줄 뿐이지 자신의 위치정보를 말해주지는 않습니다. 또한, 포커를 칠때도 상대패를 모르는 상태에서도 내가 decision을 해야되는 상황일때도 있습니다. 이것을 POMDP(Partially Observable Markov Decision Process)라고 합니다. environment의 state와 다르기 때문에, agent는 자기 자신만의 state를 표현해야만 합니다. state를 표현하는 방법은 다양합니다. history를 그대로 사용할 수도 있습니다.

Major Components of an RL Agent
Agent의 구성요소는 크게 세가지가 있습니다. policy, value function(예측), model(예측)입니다. 세가지를 다 가질 수도 있고, 한가지만 가질 수도 있습니다. agent는 자기 자신만의 environment의 표현을 가지고 있습니다.

policy
agent의 행동을 규정해줍니다 그리고 함수라는 사실을 기억하면 성질을 이해하는데 도움이 됩니다. state를 넣어주면 action을 반환합니다.(maping입니다.) policy는 주로 파이로 나타내고 두가지로 나뉠 수 있습니다. Deterministic policy는 state를 넣으면 action 하나가 결정적으로 나옵니다. Stochastic policy는 state를 주면, 여러 행동이 가능하지만 각 action별로 확률을 구한 후에 높거나 낮을 확률에 따른 action이 선택됩니다.

value function
state가 얼마나 좋은지 나타냅니다. 예를들어 게임이라면, 게임이 끝날때 까지 총 reward를 받을 것을 합산해주는 것이라고 볼 수 있습니다. 현재 state가 좋은지 안좋은지 평가해주는 것으로도 쓰입니다. 아래의 식에대해서 설명하자면, v파이(s)는 파이 policy를 따라갔을때 게임이 끝날때 까지 얻을 총 리워드의 기대값입니다. policy가 없으면 value function은 정의할 수 없습니다! 기대값이므로 확률 변수입니다.

model
model은 environment가 어떻게 될지 예측합니다. agent는 환경이 정확이 어떤지 알기 어려울때 예측할 수 있습니다. 환경을 예측한다는 것은 next reward를 예측할 수도 있고, next state (trasition)을 예측하는 것 두가지로 나뉩니다.

Maze example
maze 예시를 통해 더 자세히 이해해보도록 합니다. start에서 goal에 가는 것이 목표인 게임이 있습니다. Rewards는 한 step을 갈수록 -1을 받습니다. 왜냐하면 최대한 적은 step으로 최대한 가기 위해서입니다. 그리고 할 수 있는 action은 동,서,남,북입니다. state는 agent의 위치입니다.

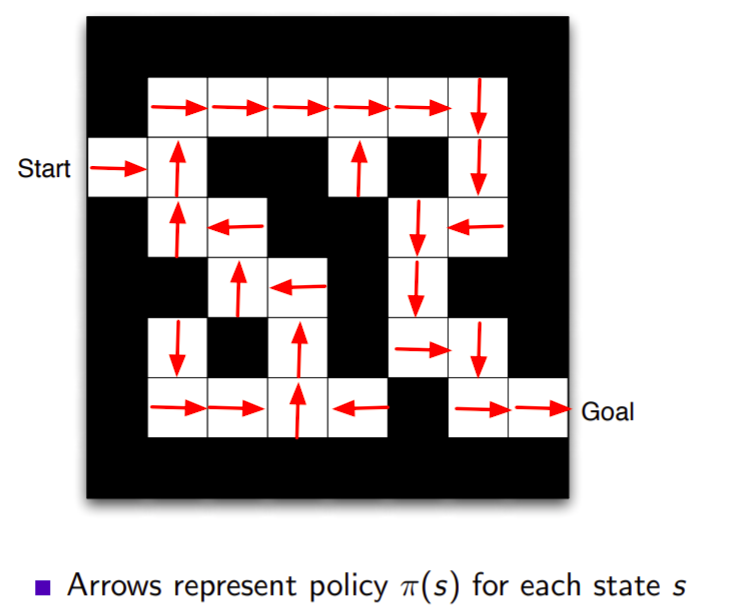
Maze example : policy
이 그림은 각 칸에서의 최적의 policy를 나타냅니다. 위 policy는 optimal policy의 예시입니다. 파이와 파이(s)에 대해서 잘 구별하도록 합시다. 파이는 임의의 policy 자체입니다. 파이(s)는 임의의 policy에서 s 상태일때의 action입니다. policy가 함수라는 사실을 기억하시면 이해하시는데 편합니다.
Maze example : value function
value function은 policy가 있어야합니다. 예시로 주어진 그림은 optiomal function입니다.

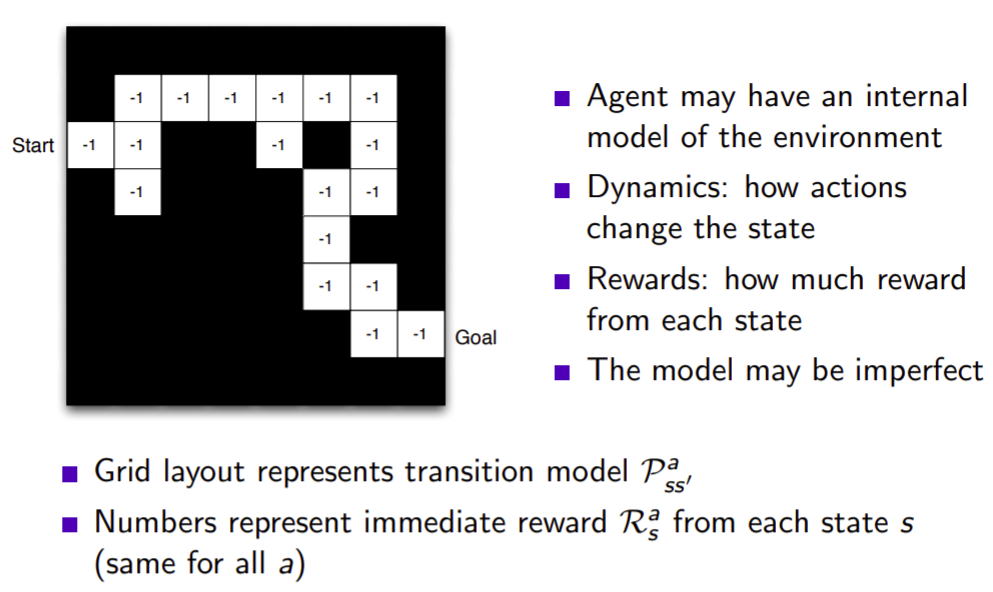
Maze example : Model
모델은 두가지는 신경써야합니다. state가 어디로가는지, reward가 몇을 주는지. model은 실제 environment가 아니라 자신이 생각하고 있는 environment가 model인 것입니다. 따라서 environment와 model은 같지 않을 수 있습니다. pss'a를 풀어서 설명해보겠습니다. transition 모델로, s에서 a를 하면 s'으로 간다는 뜻입니다.
Categorizing RL agents(1)
다음으로는 RL agents 들을 분류하는 방법입니다. value base는 value function만 있습니다. value function만 가지고도 판단할 수 있기 때문입니다. 즉, agent 역할을 할 수 있다는 것입니다. policy base는 policy만 있습니다. 마지막으로 actor critic는 policy와 value function을 둘다 가지고 있습니다.

model free는 내부적으로 모델을 만들지 않습니다. model based는 environment는 이럴 것이다라고 model로 예측해서 policy와 value funcion으로 판단하여 행동합니다. 즉, 3가지 요소를 다 갖추고 있습니다.

RL Agent Taxonomy
다양한 방법론이 가능합니다. model base는 policy, value function, model 세가지를 가지고 있습니다.

Learning and Planning
sequential decision making에서는 2가지 근본적인 문제가 있습니다. learning문제와 planning문제가 있습니다. learning 은 environment를 모르는 상태에서, environment에 던져진 후 상호작용을 통해 자신의 policy를 개선합니다. planing은 environment를 알고있습니다. environment를 알고있다는 것은 rewards가 어떻게 되는지 알고, transition이 어떻게 되는지 아는것입니다.이렇게 environment를 아냐 모르냐에 따라 차이가 있습니다.

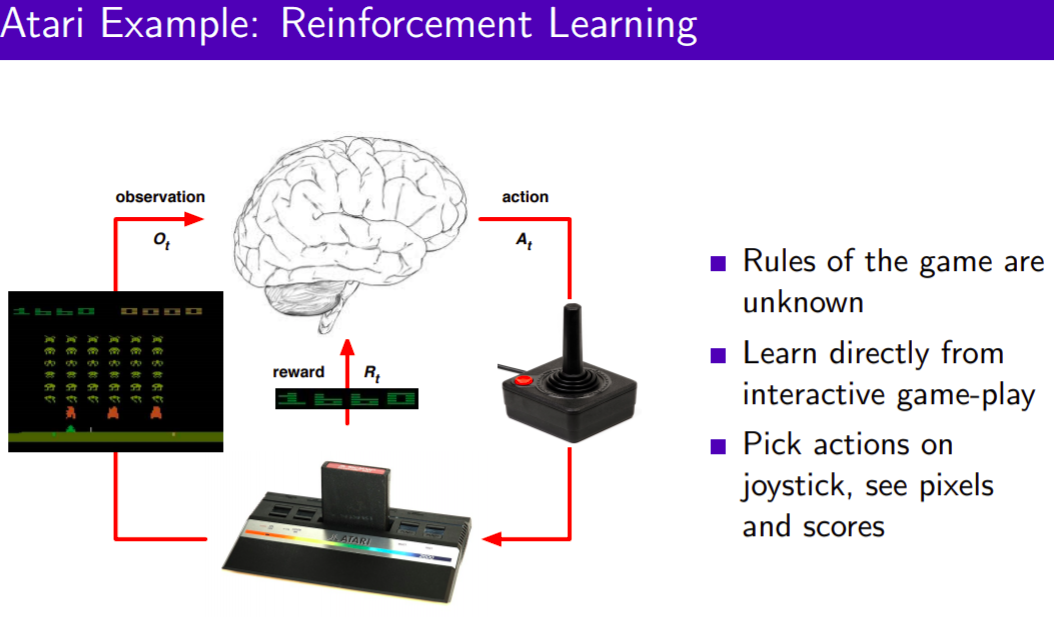
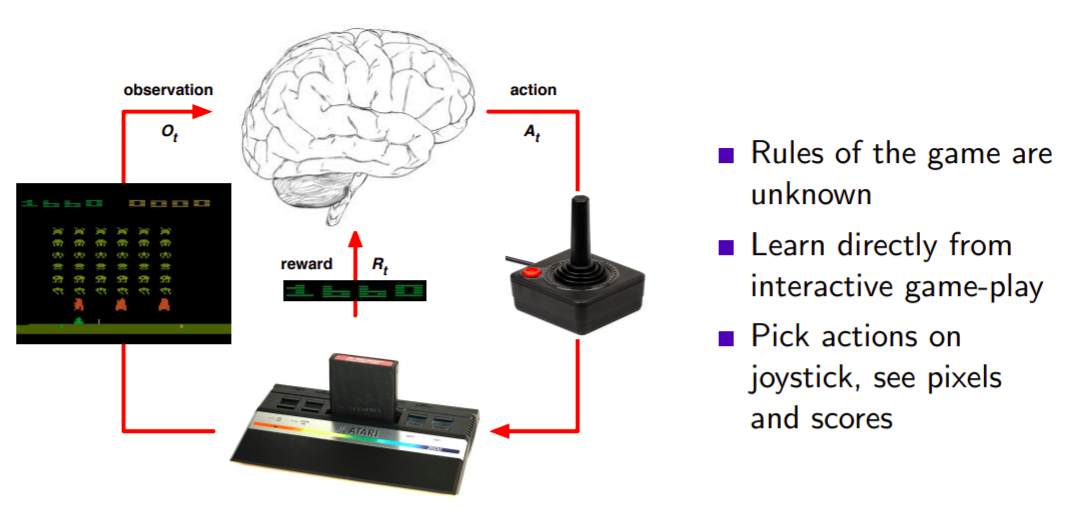
Atari Example : Reinforcement Learning
environment는 모르는 상태에서 observation이 주어지니까 agent는 interactive 하게 게임을 플레이합니다. 게임의 규칙도 모릅니다.
Atari Example : Planning
Atari 에뮬레이터가 있어서, 쿼리를 날릴 수 있습니다.

Exploration and Exploitation(1)
RL은 시행착오를 통해 학습하며, 좋은 policy를 발견해야합니다. environment와 상호작용하면서 좋은 policy를 찾는 과정입니다. 1강 앞장쪽에 나와있습니다.

또한, environment의 정보를 모아서 이해하는 과정이 있으며, 이해를 바탕으로 최선의 선택을 내리는 과정이 있습니다. 정보를 모으는 것은 exploration이며, 지금 까지 모인 정보를 바탕으로 reward를 maximize하는 것은 exploitation입니다. exploration과 exploitation은 trade off관계에 있습니다. exploration은 내가 정보가 없는 곳을 가봐야합니다. exploration은 장기적으로는 도움이 될지 모르지만 단기적으로는 효과가 나타나지 않습니다.

example
exploitation과 exploration의 예시입니다.

Prediction and Control
많은 논문에서 나오는 개념입니다. Prediction은 policy가 주어졌을때 미래를 평가를 합니다. 다른말로는 value fucntion을 잘 학습 시키는게 prediction 문제입니다. 예측이란 value function 기반으로 할 수 밖에 없기 때문입니다. control문제는 best policy를 찾는 것을 control 문제라고 합니다. 앞으로 중요하게 나올 개념중 하나입니다.

Gridworld Example : Prediction
state에 대한 value를 찾는 것이 prediction problem입니다.

Gridworld Example : Control
최적의 policy를 찾습니다.(*표시는 optimal입니다.)


http://www0.cs.ucl.ac.uk/staff/d.silver/web/Home.html
David Silver
Professor of Computer Science University College London d.silver@cs.ucl.ac.uk I am on indefinite leave of absence from UCL and not currently accepting any new students.
www0.cs.ucl.ac.uk